centos7 기준입니다.
NiFi 클러스터 모드 사용 중에 알게 된 주의할만한 사항들입니다.
NiFi 버전 2.0.0
노드 3EA (node1, node2, node4)
정리 및 요약:
1. 클러스터 환경일 시, GetSFTP 같은 프로세서는 SCHEDULING 탭 -> Execution을 Primary Node로 설정합니다.
All Nodes로 하게되면, 클러스터에 속한 모든 노드가 해당 프로세서를 실행합니다.
(이는 같은 파일을 여러 노드가 가져가려고 하기에 경쟁상태에 빠지거나,
이미 한 노드가 가져가면 File Not Found 에러의 위험이 있습니다.)
또한 GenerateFlowFile같이 플로우의 시작을 알리는 프로세서도 한 번만 실행되어야 플로우가 한 바퀴 도는 것이기에 마찬가지로 Primary Node로 설정합니다.. (빈 플로우 파일 1개를 생성하는 용도가 아닌 다른 용도면은 제외입니다.)
2. 후의 프로세서들은 All Nodes로 해야 여러 노드가 분산 작업 진행합니다. 하지만 그냥은 안되고,
로드 밸런싱 기능을 활성화 해야합니다. NiFi 1.8 버전부터 큐 수준에서 로드밸런싱 기능이 도입되었습니다.
(* 여담으로 1.8버전 이후에 이 로드밸런싱 기능이 여러 버그가 있었고 수정 후 커밋이 된것으로 보입니다. 버그 수정이 적용된 버전은 몇인지 확인 하진 못하였고, 본 포스팅은 2.0.0버전으로 진행하였고 문제 없었습니다.)
만약 로드밸런싱 기능을 안쓰고 Execution이 Primary Node인 GenerateFlowFile이 5번 실행된다면, 추후에 프로세서들이 All nodes로 설정되어있어도, 무조건 하나의 노드에서만 작업이 진행됩니다. 이유는 GenerateFlowFile이 Primary Node에서만 실행되기에 5개의 큐 모두 Primary Node인 하나의 노드에서만 쌓일테고 다음 프로세서는 큐가 쌓여있는 노드에서 작업을 실행하기에 분산 처리가 되지않습니다.
이에 큐 설정란의 Load Balance Strategy를 통해 큐를 어러 노드에 분배하여야 다음 프로세서가 각 큐가 쌓인 노드들에서 작업을 진행하여 분산 작업이 가능해집니다.
3. 5개의 큐가 쌓여있고, node1에 2개의 큐, node2에 2개의 큐, node3에 1개의 큐가 실제로 쌓여있다고 가정하면,
해당 5개의 큐를 받는 다음 프로세서의 작업은 node1에서 2번, node2에서 2번, node3에서 1번 실행됩니다. 이는 큐가 쌓인 노드에서 실제 프로세서에 대한 작업을 진행하기 때문입니다. 만약 작업한 프로세서 이후에 큐도 로드밸런싱을 했다면 5개의 큐는 또 다시 여러 노드에 재분배됩니다.
테스트:
해당 간단한 플로우로 테스트를 진행하였습니다.
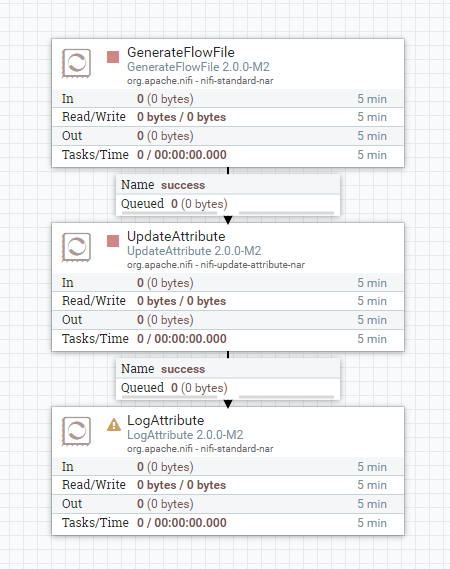
GenerateFlowFile로 flowfile을 생성하고,

UpdateAttribute를 통해 임의의 변수를 할당합니다.
LogAttribute는 큐 소진용으로 사용하였습니다.
첫 번째 주의 사항:
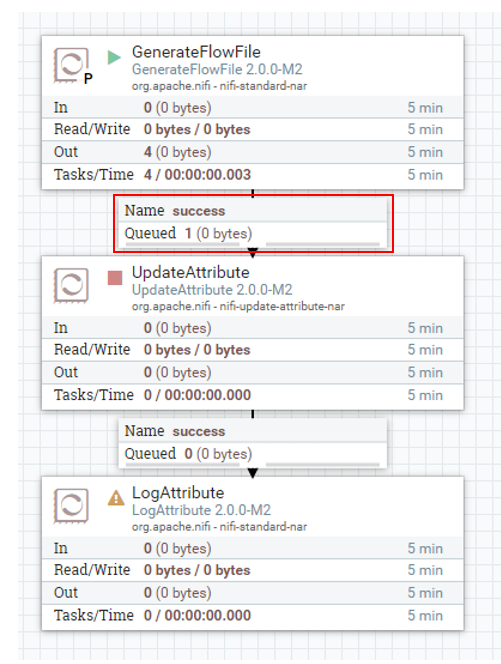
node 3개로 이루어진 NiFi 클러스터 환경입니다. 여기서 GenerateFlowFile을 실행하면,
큐 내의 플로우파일이 하나가 아닌, 3개가 생성됩니다.
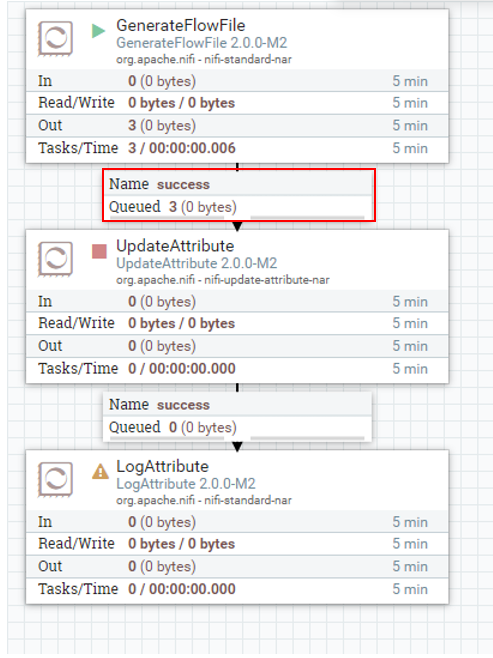
GenerateFlowFile은 보통 해당 플로우의 시작으로 많이 사용되기에, 하나의 플로우파일이 생성되어야하는데 3개가 생성되었습니다. 이는 플로우 자체가 3번 돌기에 원하는 상황이 아닙니다.
이는, 모든 클러스터에 속한 노드들이 해당 프로세서를 실행했기에 나타난 현상입니다.
저는 3대의 노드를 가진 클러스터이기에 GenerateFlowFile이 3번 실행되어, 3개의 큐가 쌓였습니다.
GenerateFlowFile 같이 한 번, 즉, 한 노드만 실행하게끔 설정하기 위해선,
프로세서 설정 -> SCHEDULING 탭 -> Execution을 All Nodes -> Primary node로 변경 해줍니다.

설정 후 재 실행 시, 원하는 대로 하나의 큐가 쌓인 모습입니다.
해당 설정은 모든 노드가 아닌, Primary Node로 선출된 하나의 노드에서만 해당 프로세서를 실행하겠다는 뜻입니다.
만약 GetSFTP같은 특정 서버의 파일을 가져오는 프로세서라면,
무조건 해당 프로세스를 Primary Node로 설정해야합니다.
All Nodes로 설정하게 된다면, 하나의 파일을 여러 노드가 가지고오는 것을 요청하게되어 경쟁 상태에 놓일 수 있고,
이미 다른 노드에서 가져갔다면, 또 다른 노드가 같은 파일을 요청하게 될테고, 이에 file not found 에러가 발생할 수 있습니다. 또한, 본 포스팅의 예제처럼 플로우의 시작을 알리는 GenerateFlowFile 같은 경우도 한 번만 실행하는 것이 원하는 의도이기에 Primary Node로 설정해야합니다.
2번 째 주의 사항:
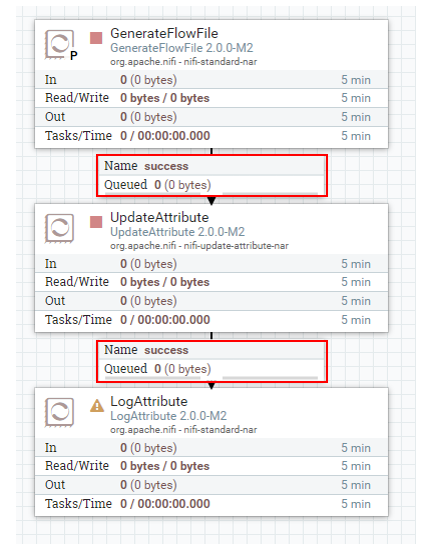
로드 밸런싱에 관한 주의 사항입니다. 아래처럼 GenerateFlowFile을 5번 실행하여 5개의 큐가 쌓였습니다.

큐를 우클릭하고 List Queue 클릭하여 상태를 체크 해보겠습니다.
5개의 큐가 모두 node2라는 서버에 쌓였습니다.

그 다음, UpdateAttribute를 실행한 후, 마찬가지로 List Queue 클릭하여 상태를 체크 해보겠습니다.
또 다시 5개의 큐가 모두 node2라는 서버에 쌓였습니다.


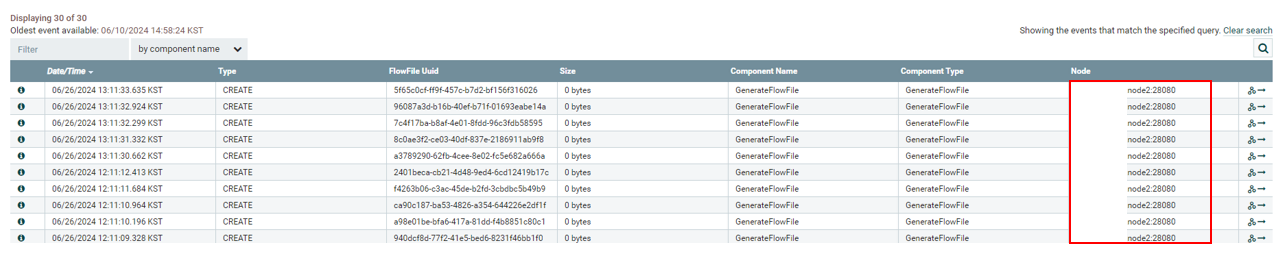
이번엔 GenerateFlowFile과 UpdateAttribute 우클릭 -> View Data provenance를 클릭하여 어떤 노드가 해당 프로세서의 작업을 수행했는지 보겠습니다.
GenerateFlowFile
node2번에서 5번 작업

UpdateAttribute
node2번에서 5번 작업

뭔가 이상합니다. 클러스터 모드를 사용한다는 건, 하나의 노드만 일하는 것이 아니라, 여러 노드들이 분산 작업을 하는 것을 원한다는 것입니다. 하지만 위 예제는 계속 하나의 노드에서만 작업이 진행되고 큐가 쌓였습니다.
이러한 현상을 해결하기위해 RPG(Remote Processor Group)을 추가로 만들어, 다른 노드들에게 큐를 배분하는 방식으로 사용한 케이스도 있었습니다.
하지만 NiFi 1.8 버전 부터 큐 수준에서 로드 밸런싱 기능을 지원하여 손쉽게 클러스터에 속한 다른 노드들에게 큐를 분배할 수 있습니다.
(* 여담으로 1.8버전 이후에 큐 수준의 로드밸런싱 기능에 몇가지 버그가 있었다합니다. 수정 후 커밋된것으로 확인되었으나, 몇 버전부터 적용되었는 지는 확인하지 못하였습니다. 본 포스팅인 2.0.0버전에서는 정상 동작합니다.)
이제 로드밸런싱 기능을 통해 큐를 여러 노드에 배분하고 작업 또한, 여러 노드가 나누어 실행하도록 설정해보겠습니다.
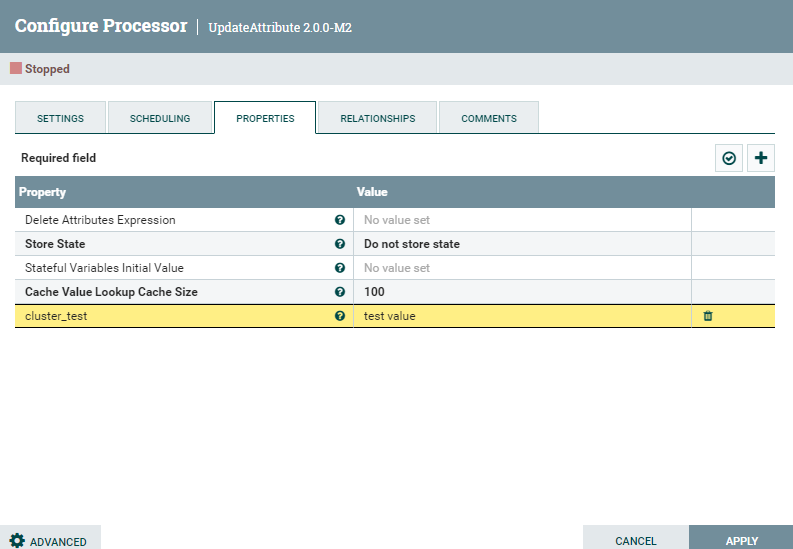
GenerateFlowFile과 UpdateAttribute 사이의 큐, UpdateAttribute 와 LogAttribute사이의 큐를
우클릭 -> Configure클릭으로 설정화면에 진입합니다.
SETTINGS 탭의 Load Balance Strategy를 Round robin으로 변경해줍니다. (두 큐 모두 설정해줍니다.)

다시 프로세서들을 각각 실행 후, 각 큐를 우클릭 -> List queue로 상태를 체크 해보겠습니다.
GenerateFlowFile과 UpdateAttribute 사이의 큐
node1서버에 2개의 큐
node2서버에 2개의 큐
node4서버에 1개의 큐

UpdateAttribute 와 LogAttribute사이의 큐
node1서버에 3개의 큐
node2서버에 2개의 큐

각 큐가 클러스터에 속한 여러 노드에 분배됨을 확인할 수 있습니다.
그렇다면 각 프로세서는 어느 노드에서 작업이 진행되었는지 확인해보겠습니다.
이전과 같이 GenerateFlowFile과 UpdateAttribute 우클릭 -> View Data provenance을 클릭하여 확인해보겠습니다.
GenerateFlowFile
GenerateFlowFile 프로세서는 항상 Primary node인 node2 서버에서 작업이 진행됨을 알 수 있습니다.
이는 포스팅 초반, 실행되는 노드를 All Nodes가 아닌 Primary node로 설정해두었기 때문입니다.
node2서버에서만 작업 진행
UpdateAttribute
이전 아무 로드밸런싱 설정을 하지 않는 5개의 큐는 node2서버에서만 작업이 진행되었지만,
로드밸런싱 설정 후 5개의 큐는 여러 노드에서 실행되었음을 알 수 있습니다.
node1서버에 2개 작업 진행
node2서버에 2개 작업 진행
node4서버에 1개 작업 진행

이렇게 클러스터링의 이유 중 하나인 로드밸런싱 기능을 통해 큐와 프로세서의 작업을 여러 노드로 분산하였습니다.
여기서 중요한 점은, 프로세서는 받는 큐 상의 각 플로우파일이 저장된 노드에서 작업이 실행된다는 점입니다.
위 예제를 다시 보시면, GenerateFlowFile에서 Primary Node로 지정했기에
GenerateFlowFile 프로세서는 모두 node2 서버에서 작업이 진행된 것을 알 수 있었고, 후
5개의 큐, 즉, 5개의 플로우 파일을 각각 node1에 2개, node2에 2개, node4에 1개를 분배하였습니다.
그리고 이 큐들을 받는 UpdateAttribute프로세서는 각 플로우파일이 저장되어있는 노드에서 작업이 진행되기에
UpdateAttribute 프로세서는 node1에서 2번 node2에서 2번 node4에서 1번 작업이 진행된 것 입니다.
그 후 UpdateAttribute 프로세서가 5개의 큐를 node1번에 3개, node2번에 2개를 배분하였는데,
그 다음 프로세서인 LogAttribute가 실행된다면 이 프로세스는 node1번에서 3번, node2번에서 2번 작업이 진행될 것입니다.
감사합니다.
참조:
https://gist.github.com/cheerupdi/bffb331447abc78934ad5a40feb83f16
12. Clustering 운영
12. Clustering 운영. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
'BigData > NiFi' 카테고리의 다른 글
| NiFi) NiFi log 디렉토리 설정 (0) | 2024.02.05 |
|---|---|
| Apache NiFi 메모리 설정 (0) | 2023.07.25 |
| Apache NiFi 설치 (0) | 2023.07.25 |