centos7 기준입니다.
6대의 서버가 준비되어있고, ntp설정,
ip설정 및 호스트네임 등록,
jdk 설정, zookeeper 설치가
완료됨을 가정합니다.
https://developer-woong.tistory.com/37
centos linux ntp enable
centos7 기준입니다 mast01~03, work01~03의 6대의 서버가 있고, mast01,mast02가 ntp 메인입니다. 1. ntp 설치 action server: all User: root pwd: - yum install -y ntp 2. ntp 설정파일 수정 (* 각 서버마다 콘피그값 다름) action
developer-woong.tistory.com
https://developer-woong.tistory.com/31
centos linux 고정 IP 설정
centos7 기준입니다. 192.168.10.101로 서버 IP를 고정시키고 싶다면, 파란색부분 추가 및 수정 vi /etc/sysconfig/network-scripts/ifcfg-eth0 고정할 IP PREFIX=24 GATEWAY=192.168.10.1 -> 운영환경이 아닌 개인 테스트 용이
developer-woong.tistory.com
https://developer-woong.tistory.com/30
centos linux 호스트네임 등록
192.168.10.1(mast01), 192.168.10.2(mast02), 192.168.10.3(mast03), 192.168.10.4(work01), 192.168.10.5(work02), 192.168.10.6(work03), 192.168.10.4(work04)의 서버들이 각각 자신의 호스트명을 등록하고 다른 서버들과 호스트명으로
developer-woong.tistory.com
https://developer-woong.tistory.com/38
centos linux java 환경변수설정
centos7 기준입니다. jdk8 버전 다운로드 후 /opt/apps/라는 디렉토리에 압축파일을 업로드 하였습니다. 추후 진행입니다. 1. 압축 해제 및 폴더명 변경 tar xvfz /opt/apps/[jdk8 TAR.GZ] mv /opt/apps/[압축해제된
developer-woong.tistory.com
https://developer-woong.tistory.com/39
Zookeeper 설치
centos7 기준입니다. mast01~03 3대의 서버에 주키퍼를 설치하겠습니다. 계정은 hadoop입니다. 1. 압축 파일 다운로드 및 해제 action server: mast01, mast02, mast03 user: root pwd: /opt/apps/ cmd: wget https://archive.apache.o
developer-woong.tistory.com
서버 세팅 및 초기 설정부터의 글은 본 블로그의 하둡 완벽설치가이드를 참조해 주세요
(* 호스트네임은 다릅니다.)
하둡에 대한 유저는 모두 hadoop:hadoop으로 통일하겠습니다.
조언과 충고 부탁드립니다!
서버(호스트네임기준):
mast01 - 네임노드, 주키퍼, 저널노드
mast02 - 네임노드, 주키퍼, 저널노드, 리소스매니저, 히스토리서버
mast03 - 주키퍼, 저널노드, 리소스매니저
work01 - 데이터노드, 노드매니저
work02 - 데이터노드, 노드매니저
work03 - 데이터노드, 노드매니저
1. 유저 및 폴더 생성
action server: all
user: root
pwd: -
cmd:
# 계정 생성 및 비밀번호 설정
adduser hadoop
passwd hadoop
# 사용할 폴더 생성
mkdir -p /opt/apps/
# 계정 전환
su - hadoop
2. 각 서버간 ssh 키 교환
action server: all
user: hadoop
pwd: /home/hadoop
cmd:
# ssh 키 생성, ssh 포트는 22002임을 가정합니다. 디폴트라면 -p 옵션을 제외해주세요.
ssh-keygen
# 각 서버간 키 교환
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@mast01 -p 22002
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@mast02 -p 22002
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@mast03 -p 22002
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@work01 -p 22002
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@work02 -p 22002
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@work03 -p 22002
3. 하둡 파일 다운로드 및 압축 해제
action server: mast01
user: root
pwd: /opt/apps
cmd:
# mast01서버에서 파일 다운로드, 설정 파일 수정 후 다른 서버들에게 배포할 예정
# 계정 전환 - root
exit
# 폴더 이동
cd /opt/apps/
# 하둡 파일 다운로드
wget https://archive.apache.org/dist/hadoop/core/hadoop-3.3.5/hadoop-3.3.5.tar.gz
# 압축해제
tar xvfz /opt/apps/hadoop-3.3.5.tar.gz
# 폴더 이동
cd /opt/apps/hadoop-3.3.5/etc/hadoop
4. 하둡 config 설정 1
action server: mast01
user: root
pwd: /opt/apps/hadoop-3.3.5/etc/hadoop
cmd:
# 데이터노드를 지정합니다.
vi workers
work01
work02
work03
# 하둡 실행 설정을 작성합니다.
vi hadoop-env.sh
.....
.....
# java 경로를 지정해줍니다.
export JAVA_HOME=/opt/apps/jdk8/
# ssh 포트가 22가 아니라면 해당 행에 포트를 지정해줍니다.
export HADOOP_SSH_OPTS="-p 22002"
.....
.....
# pid파일이 생성될 위치를 지정해줍니다.
export HADOOP_PID_DIR=/data/hadoop/pids5. 하둡 config 설정 2
action server: mast01
user: root
pwd: /opt/apps/hadoop-3.3.5/etc/hadoop
cmd:
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- hadoop nameservice 지정 -->
<value>hdfs://NNHA</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<!-- zookeeper cluster 지정 -->
<value>mast01:2181,mast02:2181,mast03:2181</value>
</property>
</configuration>
vi hdfs-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.client.failover.proxy.provider.NNHA</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<!-- namenode 관련 데이터가 저장될 경로 -->
<value>/data/hadoop/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<!-- datanode 관련 데이터가 저장될 경로 -->
<value>/data/hadoop/dfs/datanode</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<!-- journalnode 관련 데이터가 저장될 경로 -->
<value>/data/hadoop/dfs/journalnode</value>
</property>
<property>
<name>dfs.nameservices</name>
<!-- hadoop nameservice 지정 -->
<value>NNHA</value>
</property>
<property>
<name>dfs.ha.namenodes.NNHA</name>
<!-- 각 네임노드의 별칭 지정 -->
<value>name1,name2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.NNHA.name1</name>
<value>mast01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.NNHA.name2</name>
<value>mast02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.NNHA.name1</name>
<value>mast01:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.NNHA.name2</name>
<value>mast02:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://mast01:8485;mast02:8485;mast03:8485/NNHA</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence(hadoop:22002)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2560</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx2048m</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2560</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2048m</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>1024</value>
</property>
</configuration>
vi yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/yarn/rm-local-dir</value>
</property>
<property>
<name>yarn.resourcemanager.fs.state-store.uri</name>
<value>/data/hadoop/yarn/system/rmstore</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/apps/hadoop-3.3.5/etc/hadoop,
/opt/apps/hadoop-3.3.5/share/hadoop/common/*,
/opt/apps/hadoop-3.3.5/share/hadoop/common/lib/*,
/opt/apps/hadoop-3.3.5/share/hadoop/hdfs/*,
/opt/apps/hadoop-3.3.5/share/hadoop/hdfs/lib/*,
/opt/apps/hadoop-3.3.5/share/hadoop/mapreduce/*,
/opt/apps/hadoop-3.3.5/share/hadoop/mapreduce/lib/*,
/opt/apps/hadoop-3.3.5/share/hadoop/yarn/*,
/opt/apps/hadoop-3.3.5/share/hadoop/yarn/lib/*
</value>
</property>
<!-- RM HA-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>mast01:2181,mast02:2181,mast03:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- RM1 configs -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>mast02</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>mast02:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>mast02:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>mast02:8090</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>mast02:38088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>mast02:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>mast02:8033</value>
</property>
<!-- RM2 configs -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>mast03</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>mast03:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>mast03:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>mast03:8090</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>mast03:38088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>mast03:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>mast03:8033</value>
</property>
<!-- 튜닝 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>6</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>51200</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>3</value>
</property>
<property>
<name>yarn.scheduler.increment-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>10240</value>
</property>
<property>
<name>yarn.scheduler.increment-allocation-mb</name>
<value>1024</value>
</property>
</configuration>
cd /opt/apps/6. hadoop 파일 압축 및 배포
action server: mast01
user: root
pwd: /opt/apps/
cmd:
tar cvfz hadoop.tar.gz ./hadoop-3.3.5
scp -P 22002 /opt/apps/hadoop.tar.gz root@mast02:/opt/apps/
scp -P 22002 /opt/apps/hadoop.tar.gz root@mast03:/opt/apps/
scp -P 22002 /opt/apps/hadoop.tar.gz root@work01:/opt/apps/
scp -P 22002 /opt/apps/hadoop.tar.gz root@work02:/opt/apps/
scp -P 22002 /opt/apps/hadoop.tar.gz root@work03:/opt/apps/
7. hadoop 파일 압축 해제
action server: mast02. mast03, work01, work02, work03
user: root
pwd: -
cmd:
cd /opt/apps/
tar xvfz /opt/apps/hadoop.tar.gz
8. hadoop 폴더 생성 및 권한 부여
action server: all
user: root
pwd: -
cmd:
mkdir -p /data/hadoop
mkdir /data/hadoop/dfs
mkdir /data/hadoop/yarn
mkdir /data/hadoop/pids
chmod 777 /data/hadoop/pids
mkdir /opt/apps/hadoop-3.3.5/logs
chmod 777 /opt/apps/hadoop-3.3.5/logs
chown -R hadoop:hadoop /opt/apps/hadoop-3.3.5
chown -R hadoop:hadoop /data/hadoop/
9. hadoop 환경변수 설정
action server: all
user: root
pwd: -
cmd:
vi /etc/profile.d/hadoop.sh
export HADOOP_HOME=/opt/apps/hadoop-3.3.5
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
source /etc/profile.d/hadoop.sh
su - hadoop
cd /opt/apps/hadoop-3.3.5
10. hadoop 실행
action server: mast01, mast02, mast03
user: hadoop
pwd: /opt/apps/hadoop-3.3.5
cmd:
# mast01 서버 실행 (최초 1회)
./bin/hdfs zkfc -formatZK
# mast01, mast02, mast03 서버 실행
./bin/hdfs --daemon start journalnode
# mast01 서버 실행 (최초 1회, 지정한 nameservice 입력 )
./bin/hdfs namenode -format NNHA
# mast01 서버 실행
./bin/hdfs --daemon start namenode
./bin/hdfs --daemon start zkfc
./bin/hdfs --workers --daemon start datanode
# mast02 서버 실행
./bin/hdfs namenode -bootstrapStandby (최초 1회)
./bin/hdfs --daemon start namenode
./bin/hdfs --daemon start zkfc
11. HDFS 경로 생성
action server: mast01
user: hadoop
pwd: /opt/apps/hadoop-3.3.5
cmd:
hdfs dfs -mkdir /tmp
hdfs dfs -chmod 777 /tmp
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hadoop
12. YARN, History 서버 실행
action server: mast02
user: hadoop
pwd: /opt/apps/hadoop-3.3.5
cmd:
./sbin/start-yarn.sh
./bin/mapred --daemon start historyserver
13. 실행 확인
action server: all
user: hadoop
pwd: /opt/apps/hadoop-3.3.5
cmd:
# namenode
mast01:9870, mast02:9870 웹 UI 확인
# resource manager
mast02:38088, mast03:38088 웹 UI 확인
# journalnode (mast01, mast02, mast03)
netstat -nltp | grep 8485
혹은 mast01:8480, mast02:8480, mast03:8480 웹 UI 확인
# zkfc (mast01, mast02)
jps
DFSZKFailoverController
# JobHistoryServer
mast02:19888 웹 UI 확인14. namenode, resource manager HA 상태 확인
action server: mast02, mast02
user: hadoop
pwd: /opt/apps/hadoop-3.3.5
cmd:
------ namenode failover check ------
# 앞서 hdfs-site.xml 에서 설정한 네임노드 별칭
# mast01 서버에서 진행
./bin/hdfs haadmin -getServiceState name1
./bin/hdfs haadmin -getServiceState name2
# 액티브인 서버에서 실행
./bin/hdfs --daemon stop namenode
# 추후 스탠바이 네임노드가 액티브가 되었는지 확인
./bin/hdfs haadmin -getServiceState name1
./bin/hdfs haadmin -getServiceState name2
# 앞서 종료한 네임노드 기동
./bin/hdfs --daemon start namenode
------ resource manager HA check ------
mast02:38088, mast03:38088 웹 UI 접속 시
하나의 url로 리다이렉트 되는데, 스탠바이 리소스매니저의 웹으로 접근하게되면
자동으로 액티브 리소스매니저의 웹으로
redirect됨.
# 명령어확인
# mast02서버에서 실행
./bin/yarn rmadmin -getServiceState rm1
./bin/yarn rmadmin -getServiceState rm2
15. 추후 기동/종료
action server: mast01, mast02, mast02
user: hadoop
pwd: /opt/apps/hadoop-3.3.5
cmd:
----- HADOOP, YARN STOP -------
# mast02 서버에서 실행
./bin/mapred --daemon stop historyserver
./sbin/stop-yarn.sh
# mast02 서버에서 실행 (스탠바이 네임노드인 곳)
./bin/hdfs --daemon stop zkfc
./bin/hdfs --daemon stop namenode
# mast01 서버에서 실행 (액티브 네임노드인 곳)
./bin/hdfs --workers --daemon stop datanode
./bin/hdfs --daemon stop zkfc
./bin/hdfs --daemon stop namenode
# mast01, mast02, mast03 서버에서 실행
./bin/hdfs --daemon stop journalnode
./bin/hdfs --daemon stop journalnode
./bin/hdfs --daemon stop journalnode
----- HADOOP, YARN START -------
# mast01, mast02, mast03 서버에서 실행
./bin/hdfs --daemon start journalnode
./bin/hdfs --daemon start journalnode
./bin/hdfs --daemon start journalnode
# mast01 서버에서 실행
./bin/hdfs --daemon start namenode
./bin/hdfs --daemon start zkfc
./bin/hdfs --workers --daemon start datanode
# mast02 서버에서 실행
./bin/hdfs --daemon start namenode
./bin/hdfs --daemon start zkfc
./sbin/start-yarn.sh
./bin/mapred --daemon start historyserver16. 최종확인
jps

mast01:9870
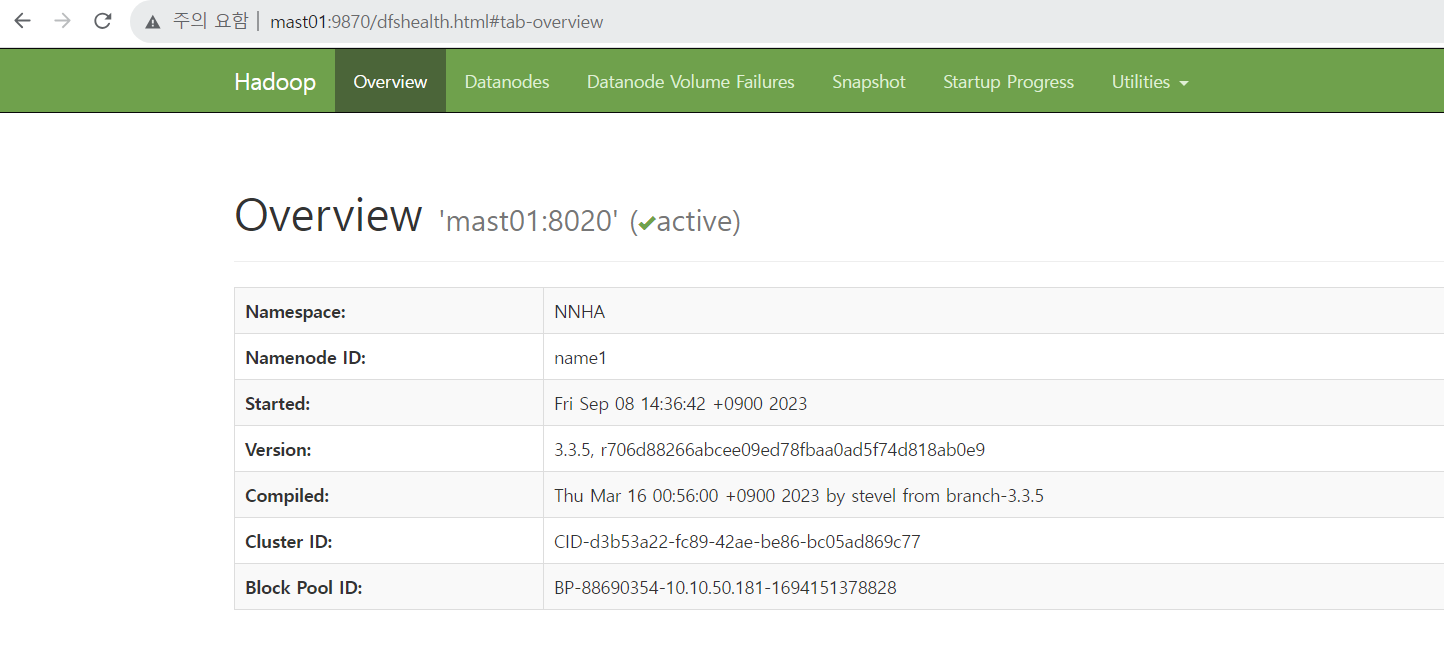
mast02:9870

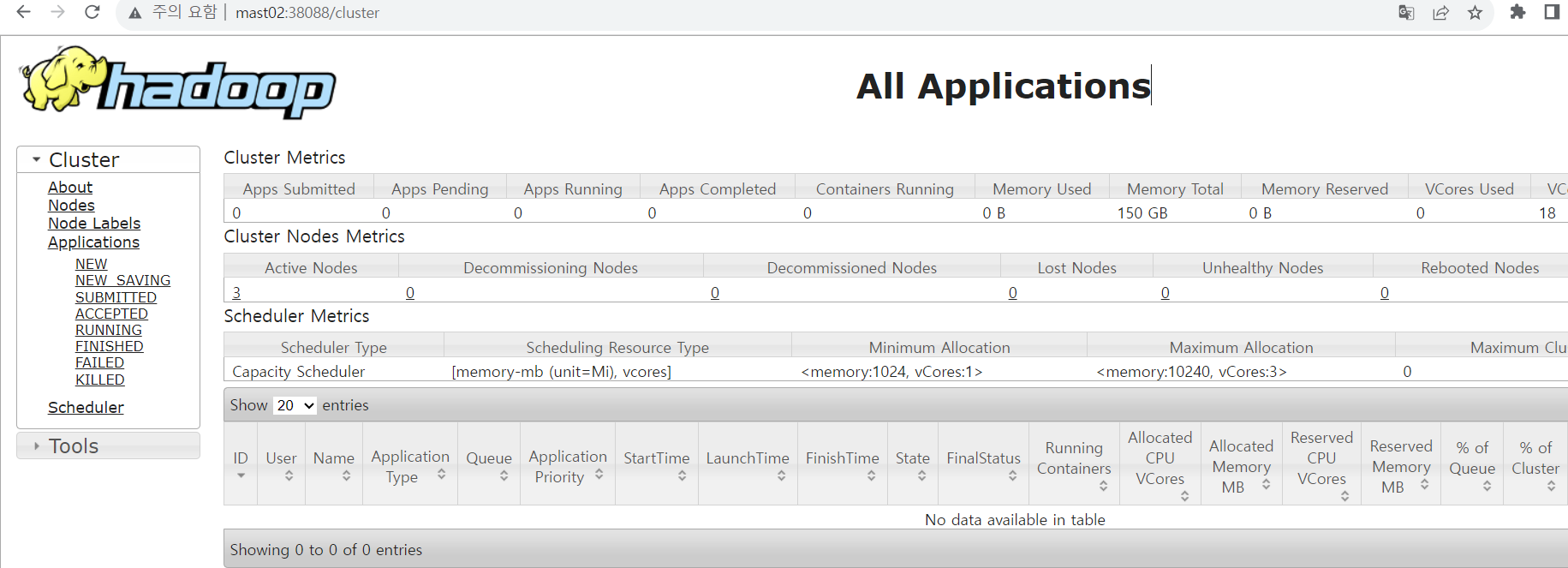
mast02:38088, mast03:38088
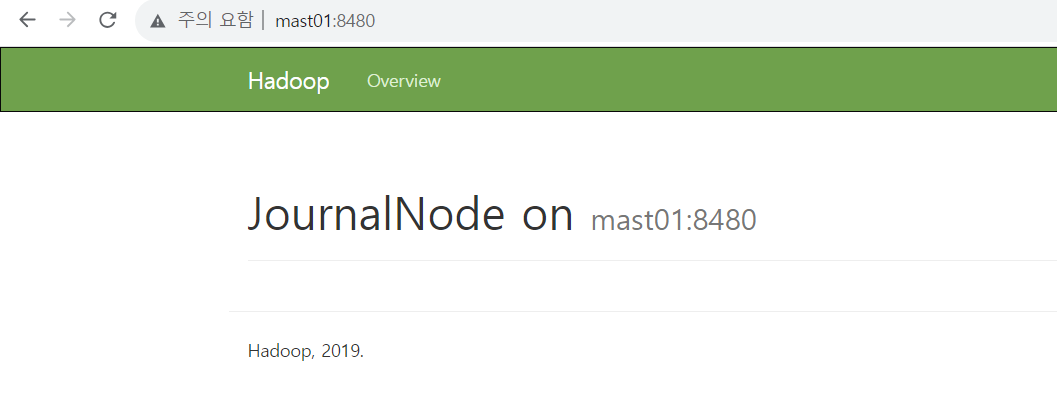
mast01,02, 03:8480


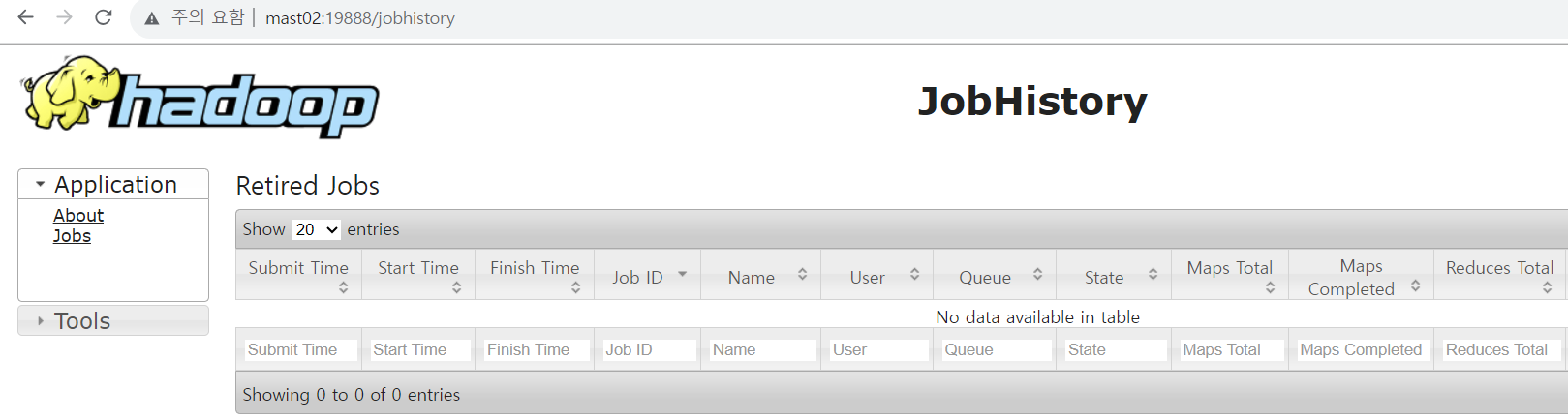
mast02:19888
wordcount 예제
# 워드카운트 테스트용 hdfs 경로 생성
hdfs dfs -mkdir /user/hadoop/testwordcount
# hadoop-env.sh 파일을 hdfs상에 업로드
hdfs dfs -put /opt/apps/hadoop-3.3.5/etc/hadoop/hadoop-env.sh /user/hadoop/testwordcount/
# 업로드한 파일을 워드카운트 및 결과를 /user/hadoop/testwordcount/output에 저장합니다.
yarn jar /opt/apps/hadoop-3.3.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar wordcount /user/hadoop/testwordcount/ /user/hadoop/testwordcount/output
# 결과를 cat합니다.
hdfs dfs -cat /user/hadoop/testwordcount/output/part-r-00000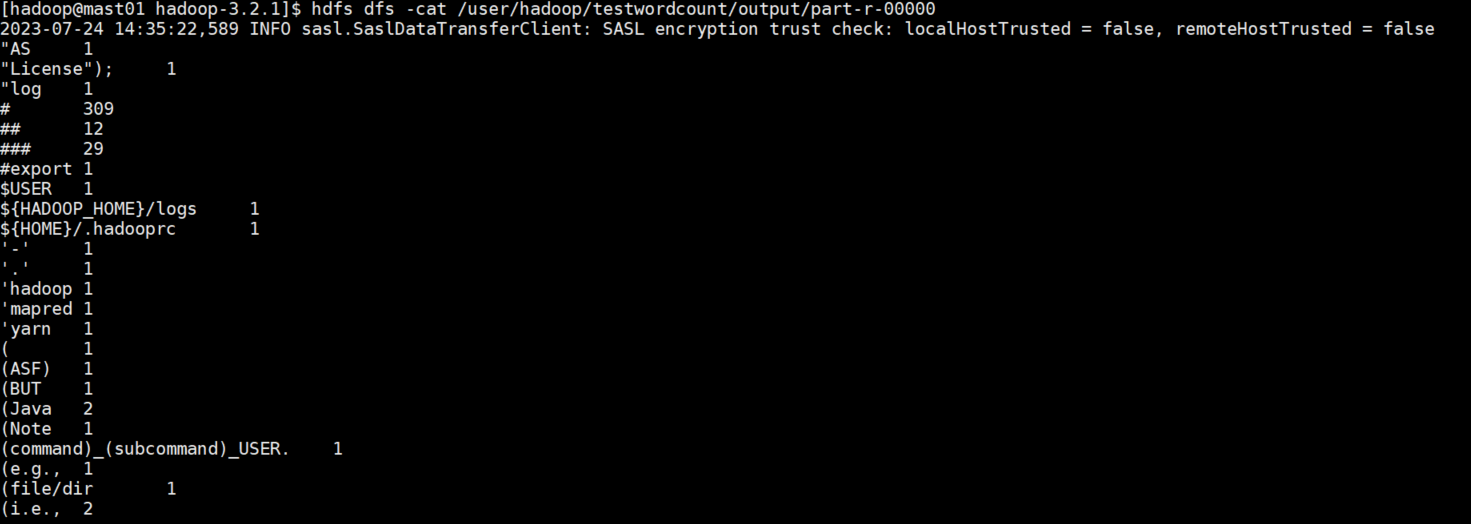
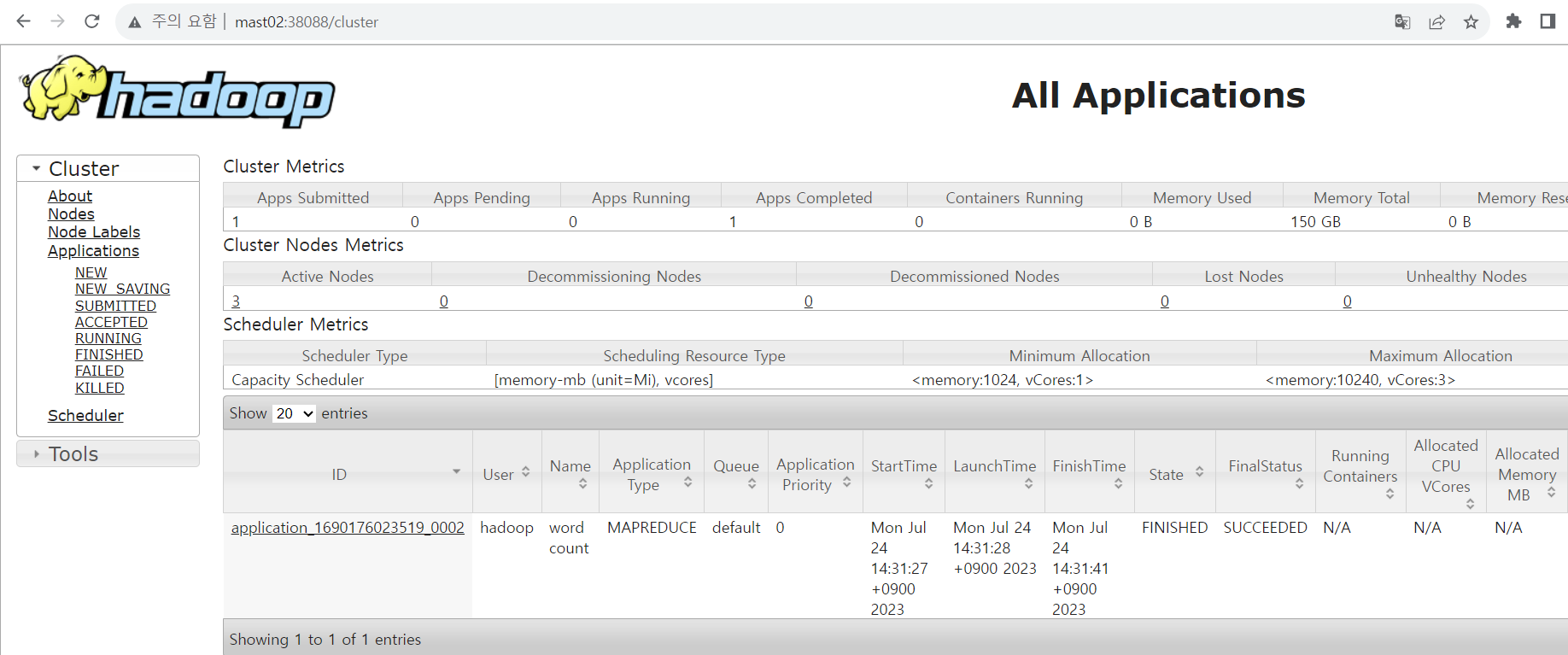
mast02:38088
긴 글 읽어주셔서 감사합니다.
'BigData > Hadoop' 카테고리의 다른 글
| yarn capacitiy 스케줄러 설정 (0) | 2023.07.26 |
|---|---|
| Yarn timelineserver 설정 (0) | 2023.07.26 |
| (하둡 설치) ep10_하둡 맵리듀스, 워드카운트 예제 (hadoop mapreduce wordcount) (2) | 2021.02.25 |
| (하둡 설치) ep09_하둡(hadoop) 실행과 종료, 트러블 슈팅 (2) | 2021.02.25 |
| (하둡 설치) ep08_하둡(hadoop)설치 및 환경 설정 (0) | 2021.02.25 |