하둡 분산 파일시스템(HDFS)와 함께 핵심 구성 요소인 MapReduce에 관해 알아본다.
하둡이란?
(하둡완벽설치!)ep02_하둡에코시스템(Hadoop EcoSystem)
하둡의 역사에 대해 궁금하다면?! developer-woong.tistory.com/6 (하둡완벽설치!) ep01_하둡(Hadoop)의 역사, 등장 배경 데이터 시대 2013, 2014년 기준으로 뉴욕증권거래소에서는 하루 4.5테라바이트의 데이터
developer-woong.tistory.com
하둡 분산 파일시스템이란(HDFS:Hadoop distributed FileSystem)?:
(하둡가이드) ep03_하둡 분산 처리 파일시스템(HDFS:Hadoop Distributed FileSystem)
하둡의 주요 구성 중 핵심 프레임워크 중 하나인 HDFS에 대해 알아본다. 하둡이란? developer-woong.tistory.com/7 (하둡완벽설치!)ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다면?! devel..
developer-woong.tistory.com
맵리듀스(MapReduce):
대용량 데이터를 분산 처리하기 위한 목적으로 개발된 프로그래밍 모델로서 구글에 의해 개발되었다. 대표적인 데이터 처리를 위한 병럴 처리 기법의 하나로 최근까지 많은 주목을 받고있다.
맵리듀스는 임의의 순서로 정렬된 데이터를 분산 처리(Map)하고 이를 다시 합치는(Reduce) 과정을 거친다.
필요성:
100개의 문서가 있고, 이 문서들에서 단어의 빈도수를 세는 프로그램을 개발한다 가정해보자. 각 문서의 크기가 1TB여서 500GB 램을 가지는 하나의 컴퓨터에서는 실행 할 수 없을 때, 분산 컴퓨팅이 없다면, 한 컴퓨터에서 저장 용량의 문제로 문서의 일부만 불러와 단어수를 세고, 결과를 어딘가에 저장한 후 메모리에서 지운 뒤, 다시 문서의 다른 일부분을 불러와 빈도수를 세는 과정을 거쳐야한다. 이 과정이 틀렸다고는 말 할 수 없지만 시간이 오래 걸린다는 단점이 존재한다. 이에 100개의 문서의 크기는 100TB이고, 500GB의 메모리를 가지는 컴퓨터 200개를 활용하여 한 번에 분산처리하는 것이 분산컴퓨팅이고 여기에 사용되는 유명한 처리 방식이 맵리듀스이다.
[맵리듀스 과정]

Input: 말 그대로 데이터를 입력하는 과정(한 문서를 예시)
ex) We hold these truths to be self-evident. Governments long established should not. Such has been the patient. .....
Splitting(<k1, v1>, key, value 값): 데이터를 쪼개어 HDFS에 저장, 나눠진 문서는 각 노드에 정해진 양만큼 할당
ex) (0, We hold these truths to be self-evident, ..)
(138, Governments long established should not ...)
(256, Such has been the patient ...)
(* 한 문서를 문장별로 나누고 key값을 부여)
Mapping(list (<k2, v2>): 맵 태스크는 위 과정의 output인 키-값(key-value)쌍을 input으로 받아 다음과 같은 리스트를 만듬, 100개의 문장이라면 100개의 리스트를 생성
ex) ('We' : 1, 'hold' : 1 ...)
('Government' : 1, 'long' : 1 ...)
('Such' : 1, 'has', 1 ...)
(* Splitting의 output인 전체 문서에서 쪼개진 각각의 문장들을 다시 단어별로 쪼개어 결과를 리스트 형식으로 생성,
이 과정에서 한 문장 중 같은 단어가 여러 번 나오더라도 value값은 1, 예를 들어 'We'라는 단어가 3번 나와도
'We':1, 'We':1, 'We':1)
Shuffling(<k2, list(v2)>): 각 문장별 단어의 맵 함수의 결과를 취합(맵 태스크의 결과를 키-값 쌍으로 변환)하고 리듀스 함수로 데이터를 전달
ex) ('We' : [1,1,1])
('Government : [1,1,1])
('Such' : [1,1,1])
(* 매핑과정의 output, 각 단어별로 문장 내에서 찾은 빈도수 리스트)
Reducing(list (<k3, v3>)): 모든 값을 합쳐 원하는 값을 추출
ex) ('We' : 100)
('Government' : 10)
Map-Reduce Input/Output
| Input | Output | |
| Split | 텍스트 | <k1, v1> |
| Map | <k1, v1> | list (<k2, v2>) |
| Shuffle | list (<k2, v2>) | <k2, list(v2)> |
| Reduce | <k2, list(v2)> | list (<k3, v3>) |
[맵리듀스 구조 (하둡 1.0 기준)]
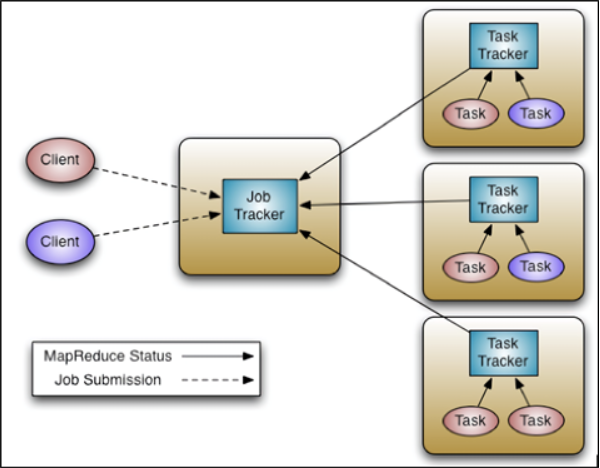
클라이언트: 사용자가 실행한 맵리듀스 프로그램과 하둡에서 제공하는 맵리듀스 API, 사용자는 맵리듀스 API로 맵리듀스 프로그램을 개발하고 하둡에서 실행 할 수 있다.
잡트래커(Job Tracker)의 역할:
- 잡(job): 클라이언트가 하둡에 실행 요청 시 발생되는 맵리듀스 프로그램은 job이라는 단위로 관리된다.
- 하둡 클러스터에 등록된 전체 잡의 스케줄링을 관리하고 모니터링 한다.
(* 스케줄링 관리: 잡을 처리하기 위해 맵과 리듀스의 실행 갯수를 계산, 계산된 맵과 리슈스를 어떤 태스크 트래커에서 실행할 지 결정 후 잡을 나눈다.)
(* 스케줄링 모니터링: 하트비트(제대로 작동하고 있는지 확인, Heart Beat)로 태스크트래커와 통신하면서 상태와 작업 정보를 받는다.
태스크트래커에 장애 발생 시 다른 대기중에 있는 태스크트래커에게 태스크를 실행한다.
하둡 클러스터 전체에서 하나만 실행된다.")
태스크트래커(Task Tracker)의 역할:
- 하둡의 데이터노드 서버에서 실행되는 데몬(사용자가 직접 제어하지 않는 백그라운드에서 여러 작업을 수행하는 프로그램)
- 사용자가 설정한 맵리듀스 프로그램을 실행한다.
- 잡트래커가 명령 시, 요청 받은 맵과 리듀스의 수만큼 맵 태스크, 리듀스 태스크를 생성한다.
(= 사용자가 만든 맵과 리듀스 프로그램이 맵 태스크, 리듀스 태스크)
하둡1.0 맵리듀스의 문제점:
- 하둡1.0의 맵리듀스 프레임워크는 무조건 맵리듀스 API로 만든 프로그램만 실행 가능했다.
- 맵리듀스 SPOF(Single Point Of Failure, 단일 고장점): 잡트래커에 문제가 생기면 태스크트래커가 작동하고 있어도 맵류드스를 전체 사용할 수 없게 된다.
- 잡트래커의 메모리 부족 시, 잡의 상태 모니터링, 새로운 잡 실행 요청 등을 못하게 된다.
- 맵리듀스는 슬롯이란 개념으로 클러스터에서 실행할 수 있는 태스크의 개수, 즉, 태스크 수행 단위로 관리하는데 실행중인 잡이 맵 슬롯만 사용하고 있거나 리듀스 슬롯만 사용한다면 다른 슬롯은 잉여자원이 되어 리소스가 낭비된다.
(* 슬롯: 한 번에 실행되는 태스크들의 묶음)
- 맵리듀스 리소스는 맵리듀스 기반의 프레임워크만 자원을 공유하기 때문에 다른 에코시스템은 자원 공유 불가
- 맵과 리듀스로 정해진 구조 외에 다른 알고리즘의 지원 한계
- 맵리듀스 잡을 실행하는 클라이언트와 맵리듀스 클러스터 버전이 반드시 동일해야한다는 점
하둡 2.0 YARN의 등장:
- 위 문제를 해결하고 효율적인 관리를 위해 하둡 2.0버전부터 YARN이 도입되었다.
[하둡의 버전 업그레이드(+YARN)]

YARN의 목표:
- 잡트래커의 주요 기능을 추상화한다.
- 잡트래커의 핵심 기능인 클러스터 자원관리와 애플리케이션 라이프 사이클 관리를 분리하고 담당하며 부하를 줄인다.
- 다양한 데이터 처리 애플리케이션이 수용 가능하다.
- 기존 맵리듀스가 반드시 맵리듀스 API로 구현된 프로그램만 실행할 수 있었다면, 얀(YARN)에서의 맵리듀스는 실행되는 여러 애플리케이션들 중 하나
얀(YARN)이란?
(하둡가이드) ep04_YARN이란?
하둡의 구성 요소 중 핵심 프레임워크인 Yarn에 대해 알아본다. 하둡이란? developer-woong.tistory.com/7 (하둡완벽설치!)ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다면?! developer-woo..
developer-woong.tistory.com
필요 지식:
주키퍼(Zookeeper)란?
developer-woong.tistory.com/11
(하둡 기초) ep06_주키퍼(Zookeeper)란?
효과적인 분산 코디네이션 시스템을 위한 주키퍼(Zookeeper)에 대해 알아본다. 하둡이란?: developer-woong.tistory.com/7 (하둡 기초) ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다면?! d..
developer-woong.tistory.com
고가용성(HA:High Availability)이란?
developer-woong.tistory.com/12
(하둡 기초) ep07_하둡 고가용성(HA:High Availability)이란?
하둡이란?: developer-woong.tistory.com/7 (하둡 기초) ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다면?! developer-woong.tistory.com/6 (하둡완벽설치!) ep01_하둡(Hadoop)의 역사, 등..
developer-woong.tistory.com
감사합니다!!
'BigData > Hadoop' 카테고리의 다른 글
| (하둡 기초) ep07_하둡 고가용성(HA:High Availability)이란? (0) | 2021.02.04 |
|---|---|
| (하둡 기초) ep06_주키퍼(Zookeeper)란? (0) | 2021.02.04 |
| (하둡 기초) ep05_YARN이란? (0) | 2021.02.03 |
| (하둡 기초) ep03_하둡 분산 처리 파일시스템(HDFS:Hadoop Distributed FileSystem) (0) | 2021.02.03 |
| (하둡 기초) ep02_하둡에코시스템(Hadoop EcoSystem) (0) | 2021.02.03 |