효과적인 분산 코디네이션 시스템을 위한 주키퍼(Zookeeper)에 대해 알아본다.
하둡이란?:
(하둡 기초) ep02_하둡에코시스템(Hadoop EcoSystem)
하둡의 역사에 대해 궁금하다면?! developer-woong.tistory.com/6 (하둡완벽설치!) ep01_하둡(Hadoop)의 역사, 등장 배경 데이터 시대 2013, 2014년 기준으로 뉴욕증권거래소에서는 하루 4.5테라바이트의 데이터
developer-woong.tistory.com
주키퍼(Zookeeper)의 필요성:
분산 애플리케이션을 작성하는 것은 매우 어려운 일이다. 가장 큰 이유는 부분 실패(Partial Failure)때문이다. 네트워크로 연결된 두 노드 사이에 메시지가 전송된 후 네트워크가 끊겼을 때 송신자는 수신자가 메시지를 수신했는지 여부를 모르게 된다. 네트워크가 끊기기 전에 잘 도착할 수도, 그렇지 않을 수도, 수신자 프로세스가 메시지는 받았지만 처리 도중 죽었을 수도 있다. 즉, 어떤 일이 일어났는지 송신자 입장에서 알 수 있는 방법은 수신자에게 다시 연결하여 물어보는 것 뿐이다. 이러한 상황이 부분 실패이며, 작업의 실패 여부조차 모르게 되는 상황이다.
물론 주키퍼를 사용한다해서 부분 실패를 절대 피할 수 있는 것은 아니지만, 안전하게 처리할 수 있는 분산 애플리케이션을 구축하기 위한 도구로서 큰 필요성을 가지고 최근까지 많은 관심을 받고있다.
주키퍼(Zookeeper)란:
주키퍼는 두 개의 네임노드를 이용한 HA를 가능하게 하는 분산 코디네이터이다.
고가용성(HA:High Availability)이란?
developer-woong.tistory.com/12
(하둡 기초) ep07_하둡 고가용성(HA:High Availability)이란?
하둡이란?: developer-woong.tistory.com/7 (하둡 기초) ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다면?! developer-woong.tistory.com/6 (하둡완벽설치!) ep01_하둡(Hadoop)의 역사, 등..
developer-woong.tistory.com
(* 분산 컴퓨팅에서 코디네이션의 예는 그룹 멤버십(Group Membership), 잠금제어(Locking), 공급/구독(Publisher/Subscriber), 리더 선정(Leader Election), 동기화(Synchornization) 등이 있다.)
하둡의 분산 상호 조정 서비스를 이용하여 분산환경에서 노드들 간 정보의 공유, Lock, 이벤트 등의 보조 기능을 제공한다. 하둡은 주키퍼를 통해 어떤 네임노드가 Active인지 혹은 Standby인지를 저장함으로서 네임도드들을 관리한다.
하둡은 기본적으로 3대의 주키퍼 서버가 할당되어있어야한다.
하둡의 이전 버전은 단일 실패 지점(SOF:Single Of Failure)라는 개념으로 네임노드에 장애 발생 시 모든 기능을 수행할 수 없는 단점이 존재하였는데 주키퍼는 이러한 장애 발생 시 부분적 실패를 안전하게 다루면서 분산 응용 프로그램을 구축할 수 있는 도구를 제공한다.

주키퍼(Zookeeper)의 특징:
- 단순한 주키퍼:
단순한 몇 개의 핵심 연산을 제공하는 간소화(Stripped-Down)된 하나의 파일시스템 이벤트와 관련된 순서화(Ordering)와 통지(Notification) 같은 추상화를 제공
- 다양한 활용:
상호조정에 필요한 다양한 데이터 구조체와 프로토콜 구축을 위한 풍부한 원천, 기초(Primitive)를 제공
- 고가용성:
클러스터상에서 동작하고, 장애 발생을 허용하며 기능 수행에 지장이 없도록 고가용성을 보장되게끔 설계
- 느슨한 상호작용 연결:
상호작용 참여자의 익명성을 보장하고 서로의 존재나 네트워크 세부사항을 모르더라도 프로세스가 서로 상호 발견, 소통할 수 있다.
- 라이브러리:
주키퍼는 상호조정 패턴에 대한 구현물과 그 방법을 무료 오픈 소스로 제공한다.
- 뛰어난 처리량:
주키퍼를 만든 야후(Yahoo)에서 테스트 해본 결과, 수백 개의 클라이언트가 만들어내는 쓰기 위주의 작업 부하 벤치마크에서 초당 10,000개가 넘는 처리량을 보였고, 일반적 사례인 읽기 위주의 작업 부하에서는 그보다 몇 배 높은 처리량을 보였다.
- 순차적인 일관성:
클라이언트로부터의 업데이트는 그들이 보내졌을 때 순서대로 적용된다.
- 원자성:
업데이트는 성공하거나 실패 둘 중 하나이다. 그 외 결과는 없다.
- 단일 시스템 이미지:
클라이언트는 연결된 서버에 관계없이 같은 시스템을 바라보는 것처럼 동작한다.
- 신뢰성, 지속성:
한 번 업데이트가 적용되면, 클라이언트가 업데이트를 덮어 쓰기 전까지 지속된다.
(= 업데이트 연산 성공 시, 내역은 유지되고 취소되지 않을 것)
- 적시성:
시스템의 클라이언트 시각적 관점은 특정 시간 내에 처리 될 수 있도록 보장된다. 뒤처진 정보를 클라이언트에게 주지 않는다.
주키퍼의 서비스(Zookeeper Service):

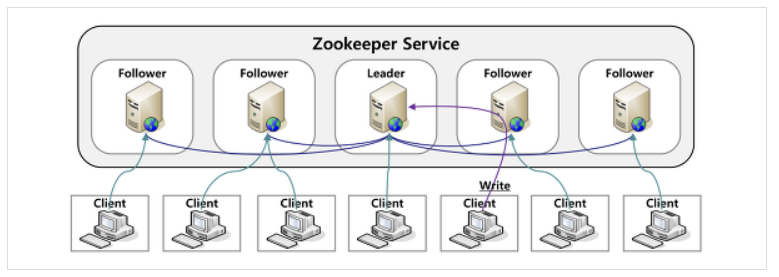
- 주키퍼 클러스터 구조는 기본적으로 복제 모드(replicated mode)로 수행되고 이러한 클러스터 구조를 앙상블이라 한다.
- 하나의 서버에만 서비스가 집중되지 않도록, 서비스를 알맞게 분산하여 동시 처리
- 하나의 서버의 처리 결과를 다른 서버들과 공유, 동기화하여 데이터 안정성 보장
- 운영(Active)서버에 문제 발생 시 다른 대기 중인 서버(Standby)를 운영서버로 바꾸며 서비스의 중지를 막음
- 분산 환경을 구성하는 서버들의 환경설정을 통합적으로 관리
- 일반적으로 3대 이상의 서버를 사용하고 홀수의 서버 갯수로 구성됨
(* 서버 간의 데이터 불일치 시 데이터 보정이 필요한데 이 때, 과반수의 룰을 적용하기 때문에 서버의 갯수를 홀수로 하는 것이 데이터 정합성 측면상 유리하다.)
- Leader 서버는 주키퍼 서버 구동시 주키퍼의 자체 내부 알고리즘에 의해 자동 선정 된다.
- Follwers 서버들은 클라이언트로부터 받은 모든 업데이트 이벤트를 리더에게 전달한다.
- 클라이언트는 모든 주키퍼 서버에서 읽을 수 있고, Leader를 통해 쓰기가 가능
- 앙상블 내에 과반수 서버의 승인이 필요하다.
(* 최소 3대의 서버, 홀수 개로 구성하는 이유)
주키퍼의 데이터 모델(Zookeeper Data Model):
주키퍼는 계층적인 네임스페이스(namespace)를 제공하며 네임스페이스 내에 존재하는 모든 개별 노드를 znode라고 부른다. 모든 znode는 데이터(바이트 배열)을 가질 수 있고 자식 znode를 가질 수도 있다.

- 절대 경로 '/'로 구분, 상대 참조가 없으며 명칭에 유니코드 문자 포함 가능, 변경 발생 시 버전 번호 증가
(= 유닉스 파일시스템 구조)
- 상대경로를 지원하지 않고 절대경로만 지원
- 데이터는 항상 전체를 읽고 쓰는 구조, znode는 1M 이하의 데이터와 자식 노드를 가질 수 있다.
영속 종류에 따른 노드 구분(Type of Znoe):
| 영구 노드(Persistent Nodes) | 클라이언트가 명시적으로 삭제하기 전까지 존재 |
| 임시 노드(Ephemeral Nodes) | 세션이 유지되는 동안 활성, 세션 종료 시 주키퍼에 의해 삭제, 자식 노드를 가실수 없다. |
| 순차 노드(Sequence Nodes) | 경로의 끝에 일정하게 증가하는 카운터의 추가, 영구 및 임시 노드 모두 적용 가능 저장하는 순서에 따라 자동으로 일련번호가 붙는 노드 |
감시(Watch):
znode가 변경 시 watch를 설정(watcher 생성)한 클라이언트에게 변화를 알려준다.

- 특정 znode에 watch를 설정해야 한다.
- watch 설정 후 생성된 watcher는 해당 znode의 변경을 알아내어 watch를 설정한 클라이언트에게 이벤트를 전달 시 해당 watcher는 삭제된다.
- 즉 한 번 설정해놓으면 지속적인 감시를 하는 watch기능이 아닌 event change 발생 시 이를 알려주고 삭제되는 one time trigger이다.
Watcher가 감지하는 znode의 변경 이벤트 종류:
| NODE_CREATE | 노드가 생성됨을 감지 |
| NODE_DELETE | 노드가 삭제됨을 감지 |
| NODE_DATA_CHANGED | 노드의 데이터가 변경됨을 감지 |
| NODE_CHILDREN_CHANGED | 자식 노드가 변경됨을 감지 |
주키퍼 연산(Zookeeper Operation):
| Create | znode 생성 부모 znode가 존재한다는 가정 |
| Delete | znode 삭제 어떤 znode도 존재하지 않는다는 가정 |
| Exists | znode의 존재 여부 확인, 메타데이터를 구함 |
| getACL, serACL | znode에 대한 ACL설정을 얻음 or 설정 |
| getChildren | znode 자식의 목록을 얻음 |
| getData, setData | znode와 관련있는 데이터를 얻음 or 저장 |
| sync | znode의 클라이언트 뷰와 주키퍼를 동기화 |
| Multi(다중 갱신) | 여러 개의 premitive 연산의 하나의 갱신단위로 묶은 후 연산의 성공 실패 여부를 반환 전역적인 불변성을 유지해야하는 분산환경의 구조체를 구축하는데 유용하다. |
필요 지식:
하둡 분산 파일시스템이란(HDFS:Hadoop distributed FileSystem)?:
(하둡 기초) ep03_하둡 분산 처리 파일시스템(HDFS:Hadoop Distributed FileSystem)
하둡의 주요 구성 중 핵심 프레임워크 중 하나인 HDFS에 대해 알아본다. 하둡이란? developer-woong.tistory.com/7 (하둡완벽설치!)ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다면?! devel..
developer-woong.tistory.com
얀(YARN)이란?
(하둡 기초) ep05_YARN이란?
하둡의 구성 요소 중 핵심 프레임워크인 Yarn에 대해 알아본다. 하둡이란? developer-woong.tistory.com/7 (하둡완벽설치!)ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다면?! developer-woo..
developer-woong.tistory.com
맵리듀스(MapReduce)란?
developer-woong.tistory.com/10
(하둡 기초) ep04_ MapReduce 맵리듀스란?
하둡 분산 파일시스템(HDFS)와 함께 핵심 구성 요소인 MapReduce에 관해 알아본다. 하둡이란? developer-woong.tistory.com/7 (하둡완벽설치!)ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다..
developer-woong.tistory.com
[참고3]over153cm.tistory.com/entry/what-is-ZooKeeper
[참고4] Hadoop The Dfinitive Guide (하둡 완벽가이드 4판) - 톰 화이트 지음, 장형석, 장정호, 임상배, 김훈동 옮김
[참고6]m.blog.naver.com/ssdyka/221038856587
감사합니다!
'BigData > Hadoop' 카테고리의 다른 글
| (하둡 설치) ep00_필요 파일 준비 과정 (0) | 2021.02.20 |
|---|---|
| (하둡 기초) ep07_하둡 고가용성(HA:High Availability)이란? (0) | 2021.02.04 |
| (하둡 기초) ep04_ MapReduce 맵리듀스란? (0) | 2021.02.04 |
| (하둡 기초) ep05_YARN이란? (0) | 2021.02.03 |
| (하둡 기초) ep03_하둡 분산 처리 파일시스템(HDFS:Hadoop Distributed FileSystem) (0) | 2021.02.03 |