하둡의 역사에 대해 궁금하다면?!
(하둡완벽설치!) ep01_하둡(Hadoop)의 역사, 등장 배경
데이터 시대 2013, 2014년 기준으로 뉴욕증권거래소에서는 하루 4.5테라바이트의 데이터가 발생 페이스북은 2,400억개의 사진을 보유, 매달 7페타바이트 증가하는 등 우리는 데이터 시대에 살아가고
developer-woong.tistory.com
하둡(Hadoop):
하나의 대형 컴퓨터를 사용하여 데이터를 처리하는 대신, 적당한 성능의 범용 컴퓨터를 클러스터화 하고, 방대한 크기의 데이터를 클러스터에서 병렬 처리하여 속도를 높이는 자바 기반의 오픈소스 프레임워크.
오늘날 빅데이터의 수집, 처리, 분석에 빼놓을 수 없는 프레임워크이다.

하둡 에코시스템(Hadoop EcoSystem):
하둡의 코어 프로젝트는 HDFS와 MapReduce이다.
이 외에도 다양한 서브 프로젝트들이 있는데, 하둡 에코시스템은 그 프레임워크를 이루고 있는
다양한 서브 프로젝트들의 모임으로 하둡의 활용성을 높여주는 생태계이다.
[하둡 생태계]

[하둡에코시스템]
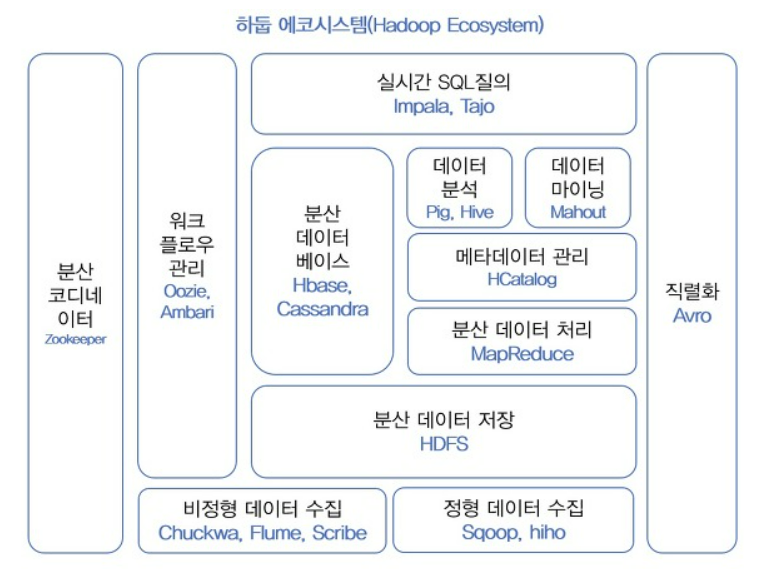
- 코어 프로젝트: HDFS(Hadoop Distributed FileSystem, 하둡 분산 파일 저장 시스템), MapReduce(분산 처리)
- 서브 프로젝트: 워크플로우 관리, 데이터 수집, 분석, 워크플로우 관리 등등 아래 설명 참조
Hadoop Framework
| Zookeeper (분산 코디네이터) | - 분산 환경에서 서버들간의 상호 조정이 필요한 다양한 서비스 제공 - 한 서버의 처리 결과를 다른 서버들에게도 전송, 동기화 - 데이터의 안전성 - 활동중인 서버(active)에서 문제 발생 시 대기 중인 서버(standby)를 운영 서버로 바꾸어 서비스를 중지 없이 제공 - 한 서버에만 서비스의 부하를 막기 위해 서비스를 알맞게 분산 - 중앙 집중식 서비스, 분산환경을 구성하는 서버 설정을 통합 관리 |
| Ooozie (워크플로우 및 코디네이터 시스템) |
- 하둡의 작업을 관리하는 워크플로우 및 코디네이터 시스템 - Java servlet 컨테이너에서 실행되는 자바 웹 어플리케이션 서버 - MapReduce, Pig 작업 같은 워크플로우 제어 |
| Avro (데이터 직렬화) | - RPC (Remote Procedure Call)과 데이터 직렬화를 지원하는 프레임워크 - JSON 형식의 데이터와 프로토콜을 정의 - 작고 빠른 Binary 포맷으로 데이터 직렬화 |
| YARN (분산 리소스 관리) | - 작업 스케줄링, 클러스터 리소스 관리 프레임워크 - MapReduce, Hive, Impala, Spark 등의 어플리케이션들을 YARN 에서 작업 |
| Mesos (Cloude 환경 리소스 관리) | - 리눅스 커널과 동일한 원칙 - 컴퓨터에 API를 제공 (Hadoop, Spark, Kafka, Elasticsearch) |
| HCatalog (테이블, 스토리지 관리) | - 하둡 기반으로 생성된 데이터를 위한 테이블, 스토리지 관리 |
| HBase (분산 Data Base) | - HDFS의 컬럼 기반 DB - Hadoop 및 HDFS 위에 Bigtable과 같은 기능을 제공 |
| HDFS (분산 파일 저장) | - 하둡의 핵심 저장소 - 하둡 네트워크에 연결된 기기에 데이터를 복제, 저장하는 분산형 파일 시스템 |
| Kudu (컬럼 기반 스토리지) | - 속성 기반 스토리지, 하둡에코시스템에 새로이 추가됨 - 데이터의 빠른 변화에 대한 빠른 분석을 위함 |
| Tajo (데이터웨어하우스 시스템) | - 고려대학교 정보통신대학 컴퓨터학과 DB연구실 박사 과정 학생들의 주도하여 개 발한 하둡 기반의 DW 시스템 - 데이터의 저장소는 HDFS 그대로 사용하고 SQL을 통해 실시간으로 데이터 조회 - Hive보다 2~3배 빠름, 클라우데라의 Impala와 비슷한 속도 - Impala는 클라우데라의 하둡을 써야하지만, Tajo는 특정 업체의 솔루션에 종속되 지 않음 |
| Chukwa (분산 환경 데이터 수집) | - 분산 환경으로 부터 생성된 데이터를 안전하게 HDFS에 저장하는 플랫폼 - 대규모 분산 시스템의 모니터링 |
| Flume (분산 환경 데이터 수집, 관리) | - 많은 양의 데이터를 수집, 집계, 이동하기 위한 분산형 서비스 - 전체 데이터의 흐름을 관리 |
| Scribe (데이터 수집 플랫폼) | - 페이스북에서 개발한 데이터 수집 플랫폼 - 쉬운 설치와 구성, 다양한 프로그래밍 언어 지원 |
| Kafka (분산 스트리밍 플랫폼) | - 데이터의 파이프라인을 구축 할 때 주로 사용 - 데이터의 흐름을 실시간으로 관리 - 데이터의 유실을 방지하고 안전한 전달을 목적으로 하는 대용량 실시간 로그처리 솔루션 |
| Sqoop (대용량 데이터 전송 솔루션) | - HDFS, RDBMS, DW, NoSQL 등의 다양한 종류의 저장소에 대용량 데이터를 빠르 게 전송하는 방법을 제공 |
| Hiho (대용량 데이터 전송 솔루션) | - Sqoop과 마찬가지로 대용량 데이터를 전송하기 위한 솔루션 - 하둡 데이터 수집을 위한 SQL과 JDBC 인터페이스 지원 |
| Pig (데이터 처리) | - 하둡에 저장된 대이터를 맵리듀스 플랫폼을 사용하지 않고 SQL과 같은 스크립트 를 활용하여 데이터를 처리 - MapReduce 프로그래밍 대체 Pig Latin이라는 자체 언어 제공 |
| Mahout (하둡 기반 데이터 마이닝 알고리즘) |
- 분석 머신러닝에 필요 알고리즘의 구축을 위한 오픈소스 프레임워크 |
| Spark (대규모 데이터 처리 엔진) | - 대규모 데이터를 빠른 속도로 처리하고 실행시켜주는 엔진 - R, Python 등 대화형 인터프린터로 사용 가능 |
| Impala (실시간 SQL 질의 시스템) | - 클라우데라에서 개발한 하둡 기반의 실시간 SQL 질의 시스템 - MapReduce를 사용하지 않고, 자체 개발한 엔진(C++ 기반 인메모리 엔진)을 사용 - 데이터 조회를 위한 인터페이스(HiveQL사용, HBase와 연동 가능) |
| Hive (데이터 웨어하우징 솔루션) | - 하둡 기반의 데이터 웨어하우징용 솔루션 (페이스북 개발) - HiveQL이라는 언어로 쉬운 데이터 분석을 지원 |
| MapReduce (대용량 데이터 분산처리) | - 정렬된 데이터를 분산 처리(Map)한 후 다시 합치는(Reduce)과정을 수행 - 하둡의 대용량 처리 핵심 기술 |
익숙해지기:
하둡 생태계를 모두 외울 필요까지는 없다. 우선 기본적인 하둡의 클러스터 구축에 먼저 익숙해져야 하고,
상황마다 필요한 프레임워크들을 사용하는 것이 좋다.
우선 HDFS, YARN, MapReduce, Zookeeper에 대해 기본 지식을 습득한다면
현재 우선적인 목표인 고가용성(HA) 하둡 클러스터 구축에 큰 도움이 될 것이다.
HDFS란?
(하둡 기초) ep03_하둡 분산 처리 파일시스템(HDFS:Hadoop Distributed FileSystem)
하둡의 주요 구성 중 핵심 프레임워크 중 하나인 HDFS에 대해 알아본다. 하둡이란? developer-woong.tistory.com/7 (하둡완벽설치!)ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다면?! devel..
developer-woong.tistory.com
YARN이란?
(하둡 기초) ep05_YARN이란?
하둡의 구성 요소 중 핵심 프레임워크인 Yarn에 대해 알아본다. 하둡이란? developer-woong.tistory.com/7 (하둡완벽설치!)ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다면?! developer-woo..
developer-woong.tistory.com
MapReduce란?
developer-woong.tistory.com/10
(하둡 기초) ep04_ MapReduce 맵리듀스란?
하둡 분산 파일시스템(HDFS)와 함께 핵심 구성 요소인 MapReduce에 관해 알아본다. 하둡이란? developer-woong.tistory.com/7 (하둡완벽설치!)ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다..
developer-woong.tistory.com
Zookeeper란?
developer-woong.tistory.com/11
(하둡 기초) ep06_주키퍼(Zookeeper)란?
효과적인 분산 코디네이션 시스템을 위한 주키퍼(Zookeeper)에 대해 알아본다. 하둡이란?: developer-woong.tistory.com/7 (하둡 기초) ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다면?! d..
developer-woong.tistory.com
고가용성(HA:High Availability)이란?
developer-woong.tistory.com/12
(하둡 기초) ep07_하둡 고가용성(HA:High Availability)이란?
하둡이란?: developer-woong.tistory.com/7 (하둡 기초) ep02_하둡에코시스템(Hadoop EcoSystem) 하둡의 역사에 대해 궁금하다면?! developer-woong.tistory.com/6 (하둡완벽설치!) ep01_하둡(Hadoop)의 역사, 등..
developer-woong.tistory.com
[참고2]butter-shower.tistory.com/73
감사합니다!!
'BigData > Hadoop' 카테고리의 다른 글
| (하둡 기초) ep04_ MapReduce 맵리듀스란? (0) | 2021.02.04 |
|---|---|
| (하둡 기초) ep05_YARN이란? (0) | 2021.02.03 |
| (하둡 기초) ep03_하둡 분산 처리 파일시스템(HDFS:Hadoop Distributed FileSystem) (0) | 2021.02.03 |
| (하둡 기초) ep01_하둡(Hadoop)의 역사와 특징 (0) | 2021.02.03 |
| (하둡 기초) ep00_프롤로그 (0) | 2021.02.03 |