# 본 환경에서 zookeeper는 hadoop 계정으로 실행됩니다.
su - hadoop
cd /opt/apps/zookeeper-3.5.10
vi conf/zoo.cfg
# 맨 아래줄에 추가합니다.
4lw.commands.whitelist=mntr,conf,ruok
# zookeeper를 재기동합니다.
./bin/zkServer.sh restart
# zookeeper 상태를 확인합니다. (1 leader, 2 follower)
./bin/zkServer.sh status
# root계정으로 전환합니다.
exit
# 추후 solr가 사용할 데이터 및 로그 폴더를 생성합니다.
mkdir /data/solr
mkdir /data/solr/log
chown -R hadoop:hadoop /data/solr
2. solr 파일 다운로드 및 압축 해제
action server: mast01, mast02, mast03
user: root
pwd: /opt/apps/
cmd:
cd /opt/apps/
wget https://archive.apache.org/dist/lucene/solr/8.11.2/solr-8.11.2.tgz
tar xvfz solr-8.11.2.tgz
chown -R mhadoop:hadoop solr-8.11.2
su - hadoop
cd /opt/apps/solr-8.11.2
3. solr 설정 파일 수정
action server: mast01, mast02, mast03
user: hadoop
pwd: /opt/apps/solr-8.11.2/
cmd:
vi bin/solr.in.sh
# zookeeper 호스트를 지정합니다.
ZK_HOST="mast01:2181,mast02:2181,mast03:2181/solr-cloud"
# chroot가 없으면 생성합니다.
ZK_CREATE_CHROOT=true
# 각 서버별 호스트명을 기입합니다. 서버별로 다른 값입니다.
SOLR_HOST="mast01" (mast02, mast03)
# 위 에서 지정한 solr 로그폴더를 지정합니다.
SOLR_LOGS_DIR=/data/solr/log
# 위 에서 지정한 solr 데이터 폴더를 지정합니다.
SOLR_DATA_HOME=/data/solr
# solr가 사용할 java 메모리 사이즈입니다.
SOLR_JAVA_MEM="-Xms512m -Xmx1g"
# solr.xml 파일을 solr 데이터 폴더에 복사합니다.
cp server/solr/solr.xml /data/solr/
4. solr 실행 및 확인
action server: mast01, mast02, mast03
user: hadoop
pwd: /opt/apps/solr-8.11.2/
cmd:
./bin/solr start -cloud
mast01:8983 ,mast02:8983, mast03:8983 확인 (디폴트포트)
5. znode 확인
action server: mast01
user: hadoop
pwd: /opt/apps/solr-8.11.2/
cmd:
/opt/apps/zookeeper-3.5.10/bin/zkCli.sh
ls /solr-cloud
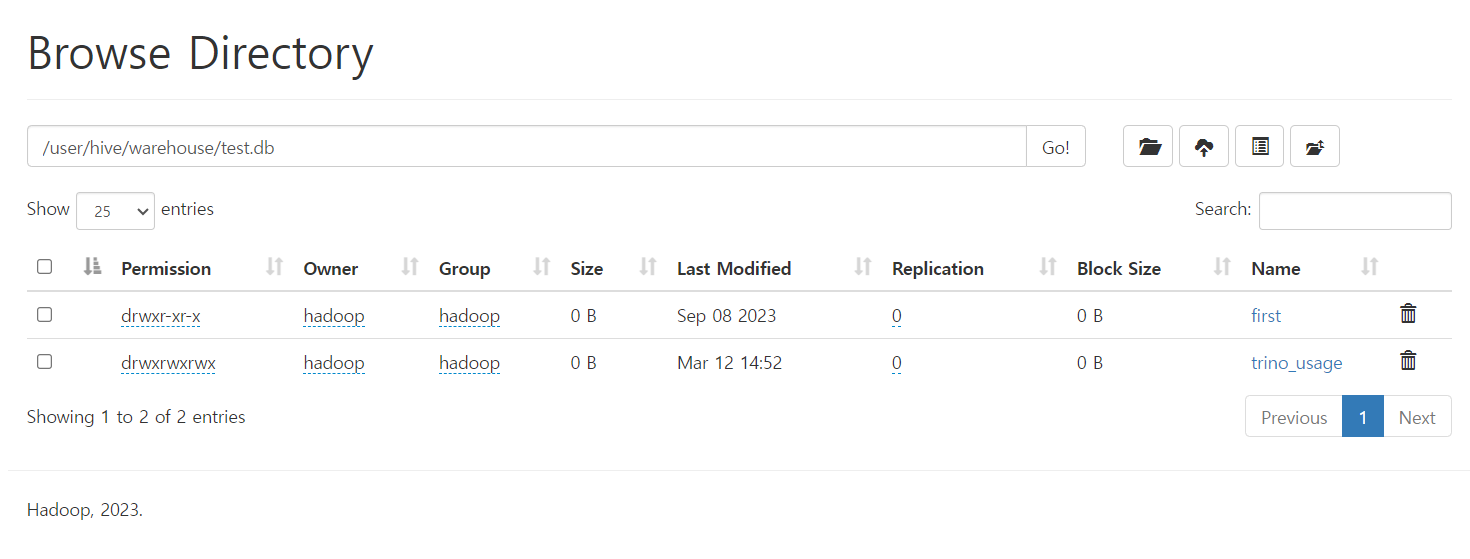
기존에 존재하지않았던 solr-cloud znode가 생성되었습니다.
추가명령어:
# 위 설정한 solr.in.sh 파일 설정에 따라 실행 명령어가 달라집니다.
/opt/apps/solr/bin/solr start
# solr를 클라우드모드로 실행합니다.
-cloud
# zookeeper 클러스터의 호스트입니다. solr.in.sh 내 ZK_HOST를 지정하여 생략하였습니다.
-z ex-util02:2181,ex-nn01:2181,ex-nn02:2181/solr-cloud
# solr 포트 지정입니다. 디폴트 8983입니다. solr.in.sh 내 SOLR_PORT를 지정하거나,
# 실행 명령어 내에 지정할 수 있습니다.
-p 8983
# solr.in.sh파일에 값을 지정함에 따라 아래와 같이 실행하였습니다.
./bin/solr start -cloud
cd /opt/apps/trino/etc
mkdir catalog
cd catalog
vi hive.properties
connector.name=hive
# mast02에 hive가 존재합니다.
hive.metastore.uri=thrift://mast02:9083
# 제 환경에서는 trino가 설치된 서버에 hadoop도 설치되어있어 아래와 같이 지정해주었습니다.
# 만약 trino가 설치된 서버에 hadoop이 설치되어있지않다면, core-site.xml, hdfs-site.xml을
# hadoop이 설치된 서버에서 가져와 적절한 경로에 위치시키고, 아래 설정을 수정해주시면 됩니다.
# core-site.xml, hdfs-site.xml이 필요합니다.
hive.config.resources=/opt/apps/hadoop-3.3.5/etc/hadoop/core-site.xml,/opt/apps/hadoop-3.3.5/etc/hadoop/hdfs-site.xml
# 경로 이동
cd /opt/apps/trino
2. trino 재기동
action server: mast01, work01, work02, work03
user: hadoop
pwd: /opt/apps/trino/
cmd:
./bin/launcher stop
./bin/launcher start
3. trino cli 파일 준비
action server: mast01
user: hadoop
pwd: /opt/apps/trino/
cmd:
# trino-cli-435-executable.jar 파일을 mast01 서버에 위치 시킵니다.
# 파일은 공식 홈페이지 내 에서 다운로드 받았습니다.
cp trino-cli-435-executable.jar /opt/apps/trino/bin/
# root 전환
exit
# 권한 부여
chwon -R hadoop:hadoop /opt/apps/trino
# 계정 전환 및 경로 이동
su - hadoop
cd /opt/apps/trino/bin
# 실행권한 부여
chmod 755 trino-cli-435-executable.jar
4. trino cli 확인
action server: mast01
user: hadoop
pwd: /opt/apps/trino/
cmd:
# 코디네이터 서버 url을 지정해줍니다.
./bin/trino-cli-435-executable.jar --server http://mast01:18081
show catalogs;
# 추가
vi /etc/security/limits.conf
hadoop soft nofile 131072
hadoop hard nofile 131072
hadoop soft nproc 128000
hadoop hard nproc 128000
3. trino server 파일 다운로드 및 압축 해제
action server: mast01, work01, work02, work03
user: root
pwd: /opt/apps/
cmd:
# https://repo1.maven.org/maven2/io/trino/trino-server/435/
# 위 링크에서 trino-server-435.tar.gz 파일을 다운로드 후,
# 각 서버의 /opt/apps/ 경로에 sftp를 통해 위치시켜주었습니다.
# wget으로 서버에서 직접 다운로드하셔도 무방합니다.
# 제 환경에서는 시간이 다소 걸려 사이트에서 직접 다운로드하였습니다.
# 경로 이동 및 압축 해제
cd /opt/apps
tar xvfz /opt/apps/trino-server-435.tar.gz
# 심볼릭 링크 설정
ln -s trino-server-435 trino
# 권한 부여
chown -R hadoop:hadoop trino-server-435
chown -R hadoop:hadoop trino
# 계정 전환
su - hadoop
# 경로 이동
cd /opt/apps/trino/bin
4. trino 실행 파일 수정
action server: mast01, work01, work02, work03
user: hadoop
pwd: /opt/apps/trino/bin
cmd:
vi launcher
# 위 설치한 jdk17을 지정해줍니다.
export JAVA_HOME=/opt/apps/jdk17
export PATH=$JAVA_HOME/bin:$PATH
exec "$(dirname "$0")/launcher.py" "$@"
vi launcher.py
# 441번째 줄
# 주석처리
#o.pid_file = realpath(options.pid_file or pathjoin(o.data_dir, 'var/run/launcher.pid'))
#o.launcher_log = realpath(options.launcher_log_file or pathjoin(o.data_dir, 'var/log/launcher.log'))
#o.server_log = abspath(options.server_log_file or pathjoin(o.data_dir, 'var/log/server.log'))
# log,pid파일을 다른 디렉토리로 지정하여 관리합니다.
o.pid_file = '/data/trino/pids/launcher.pid'
o.launcher_log = '/data/trino/log/launcher.log'
o.server_log = '/data/trino/log/server.log'
# 경로 생성 및 권한 부여
exit
mkdir -p /data/trino/pids
mkdir -p /data/trino/log
chown -R hadoop:hadoop /data/trino/
su - hadoop
cd /opt/apps/trino/
5. trino 설정 파일 수정 (코디네이터 서버)
action server: mast01
user: hadoop
pwd: /opt/apps/trino
cmd:
mkdir etc
# /opt/apps/trino/etc
cd etc
# 코디네이터, 워커 서버 다르게 설정합니다.
vi node.properties
node.environment=trino_cluster
# 해당 부분 각 서버별로 다르게 설정합니다.
# 꼭 서버 호스트명일 필요는 없지만, trino cluster 내 유일한 값이어야합니다.
node.id=mast01
node.data-dir=/data/trino
# 코디네이터, 워커 서버 다르게 설정합니다.
vi config.properties
query.max-memory-per-node=1GB
http-server.http.port=18081
# 코디네이터 서버 지정입니다.
coordinator=true
# 코디네이터 서버임과 동시에 워커 서버로도 활용한다는 config입니다.
node-scheduler.include-coordinator=true
# 코디네이터 서버 url입니다.
discovery.uri=http://mast01:18081
query.max-memory=2GB
# 코디네이터, 워커 서버 같게 설정
vi jvm.config
-server
-Xmx2G
-XX:InitialRAMPercentage=80
-XX:MaxRAMPercentage=80
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-XX:+UnlockDiagnosticVMOptions
-XX:+UseAESCTRIntrinsics
-XX:-G1UsePreventiveGC
# 코디네이터, 워커 서버 같게 설정합니다.
vi log.properties
io.trino=INFO
6. trino 설정 파일 수정 (워커 서버)
action server: work01, work02, work03
user: hadoop
pwd: /opt/apps/trino
cmd:
mkdir etc
# /opt/apps/trino/etc
cd etc
# 코디네이터, 워커 서버 다르게 설정합니다.
vi node.properties
node.environment=trino_cluster
# 해당 부분 각 서버별로 다르게 설정해야합니다.
# 꼭 서버 호스트명일 필요는 없지만, trino cluster 내 유일한 값이어야합니다.
node.id=work01 (work02, work03 각각 설정)
node.data-dir=/data/trino
# 코디네이터, 워커 서버 다르게 설정합니다.
vi config.properties
query.max-memory-per-node=1GB
http-server.http.port=18081
# 코디네이터 서버 지정입니다.
# 워커 서버이기 때문에 false로 지정합니다
coordinator=false
# 코디네이터 서버임과 동시에 워커 서버로도 활용한다는 config입니다.
# 워커 서버이기 때문에 false로 지정합니다
node-scheduler.include-coordinator=false
# 코디네이터 서버 url입니다.
discovery.uri=http://mast01:18081
query.max-memory=2GB
# 코디네이터, 워커 서버 같게 설정합니다.
vi jvm.config
-server
-Xmx2G
-XX:InitialRAMPercentage=80
-XX:MaxRAMPercentage=80
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-XX:+UnlockDiagnosticVMOptions
-XX:+UseAESCTRIntrinsics
-XX:-G1UsePreventiveGC
# 코디네이터, 워커 서버 같게 설정합니다.
vi log.properties
io.trino=INFO
7. trino 기동
action server: mast01, work01, work02, work03
user: hadoop
pwd: /opt/apps/trino/etc/
cmd:
# 전체 서버 동일합니다.
cd /opt/apps/trino
./bin/launcher start
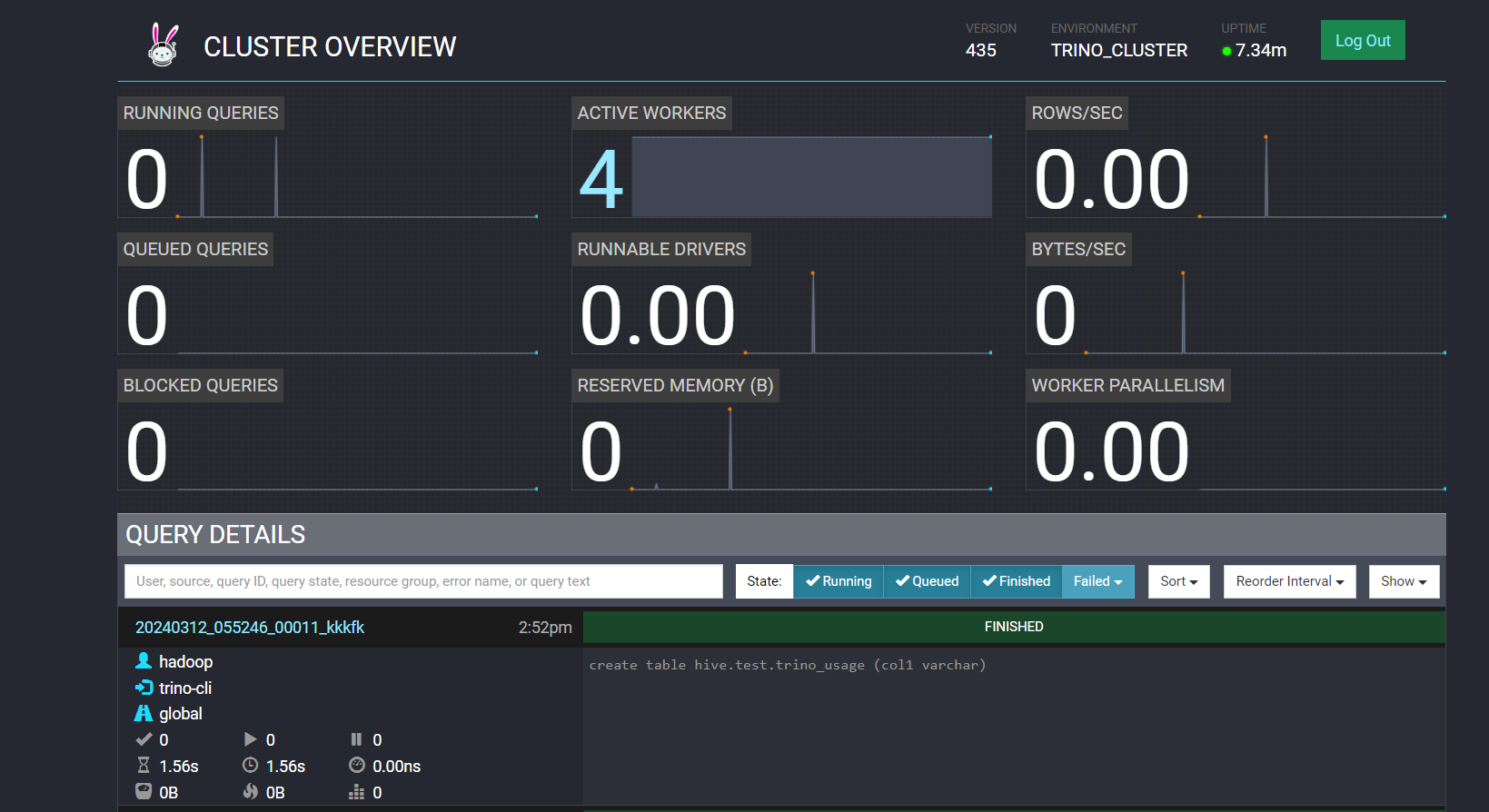
mast01:18081 확인
* 다소 시간이 흐른 뒤 worker 서버들이 인식됩니다. 계정 설정이 안된 상태이기에 로그인 시 hadoop으로 접속하였습니다.
# 경로 이동
cd /opt/apps
# 압축파일 다운로드
wget https://archive.apache.org/dist/zeppelin/zeppelin-0.10.1/zeppelin-0.10.1-bin-all.tgz
# 압축 해제
tar xvfz zeppelin-0.10.1-bin-all.tgz
# 폴더명변경
mv zeppelin-0.10.1-bin-all zeppelin-0.10.1
# 권한 부여
chown -R hadoop:hadoop zeppelin-0.10.1
su - hadoop
cd /opt/apps/zeppelin-0.10.1
2. zeppelin 유저 비밀번호 설정
action server: mast01
user: hadoop
pwd: /opt/apps/zeppelin-0.10.1
cmd:
cd conf
cp shiro.ini.template shiro.ini
# admin 유저 비밀번호 설정
vi shiro.ini
.....
.....
[users]
# List of users with their password allowed to access Zeppelin.
# To use a different strategy (LDAP / Database / ...) check the shiro doc at http://shiro.apache.org/configuration.html#Configuration-INISections
# To enable admin user, uncomment the following line and set an appropriate password
# 해당 부분 추가
admin = 1234, admin
user1 = password2, role1, role2
user2 = password3, role3
user3 = password4, role2
.....
.....
WARN [RS-EventLoopGroup-1-3] concurrent.DefaultPromise: An exception was thrown by org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper$4.operationComplete() java.lang.IllegalArgumentException: object is not an instance of declaring class at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.hbase.io.asyncfs.ProtobufDecoder.<init>(ProtobufDecoder.java:69) at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper.processWriteBlockResponse(FanOutOneBlockAsyncDFSOutputHelper.java:343) at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper.access$100(FanOutOneBlockAsyncDFSOutputHelper.java:112) at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper$4.operationComplete(FanOutOneBlockAsyncDFSOutputHelper.java:425) at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:577) at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:551) at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:490) at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.addListener(DefaultPromise.java:183) at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper.initialize(FanOutOneBlockAsyncDFSOutputHelper.java:419) at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper.access$300(FanOutOneBlockAsyncDFSOutputHelper.java:112) at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper$5.operationComplete(FanOutOneBlockAsyncDFSOutputHelper.java:477) at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper$5.operationComplete(FanOutOneBlockAsyncDFSOutputHelper.java:472) at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:577) at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.notifyListeners0(DefaultPromise.java:570) at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:549) at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:490) at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.setValue0(DefaultPromise.java:615) at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.setSuccess0(DefaultPromise.java:604) at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.trySuccess(DefaultPromise.java:104) at org.apache.hbase.thirdparty.io.netty.channel.DefaultChannelPromise.trySuccess(DefaultChannelPromise.java:84) at org.apache.hbase.thirdparty.io.netty.channel.epoll.AbstractEpollChannel$AbstractEpollUnsafe.fulfillConnectPromise(AbstractEpollChannel.java:615) at org.apache.hbase.thirdparty.io.netty.channel.epoll.AbstractEpollChannel$AbstractEpollUnsafe.finishConnect(AbstractEpollChannel.java:653) at org.apache.hbase.thirdparty.io.netty.channel.epoll.AbstractEpollChannel$AbstractEpollUnsafe.epollOutReady(AbstractEpollChannel.java:529) at org.apache.hbase.thirdparty.io.netty.channel.epoll.EpollEventLoop.processReady(EpollEventLoop.java:465) at org.apache.hbase.thirdparty.io.netty.channel.epoll.EpollEventLoop.run(EpollEventLoop.java:378) at org.apache.hbase.thirdparty.io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:989) at org.apache.hbase.thirdparty.io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) at org.apache.hbase.thirdparty.io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30) at java.lang.Thread.run(Thread.java:748)
${org.apache.nifi.bootstrap.config.log.dir}의 값을 /data/nifi/log로 변경하였습니다.
# vi ${NIFI_HOME}/conf/logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<configuration scan="true" scanPeriod="30 seconds">
<contextListener class="ch.qos.logback.classic.jul.LevelChangePropagator">
<resetJUL>true</resetJUL>
</contextListener>
<appender name="APP_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/data/nifi/log/nifi-app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!--
For daily rollover, use 'app_%d.log'.
For hourly rollover, use 'app_%d{yyyy-MM-dd_HH}.log'.
To GZIP rolled files, replace '.log' with '.log.gz'.
To ZIP rolled files, replace '.log' with '.log.zip'.
-->
<fileNamePattern>/data/nifi/log/nifi-app_%d{yyyy-MM-dd_HH}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<!-- keep 30 log files worth of history -->
<maxHistory>30</maxHistory>
</rollingPolicy>
<immediateFlush>true</immediateFlush>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
<appender name="USER_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/data/nifi/log/nifi-user.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--
For daily rollover, use 'user_%d.log'.
For hourly rollover, use 'user_%d{yyyy-MM-dd_HH}.log'.
To GZIP rolled files, replace '.log' with '.log.gz'.
To ZIP rolled files, replace '.log' with '.log.zip'.
-->
<fileNamePattern>/data/nifi/log/nifi-user_%d.log</fileNamePattern>
<!-- keep 30 log files worth of history -->
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
<appender name="BOOTSTRAP_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/data/nifi/log/nifi-bootstrap.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--
For daily rollover, use 'user_%d.log'.
For hourly rollover, use 'user_%d{yyyy-MM-dd_HH}.log'.
To GZIP rolled files, replace '.log' with '.log.gz'.
To ZIP rolled files, replace '.log' with '.log.zip'.
-->
<fileNamePattern>/data/nifi/log/nifi-bootstrap_%d.log</fileNamePattern>
<!-- keep 5 log files worth of history -->
<maxHistory>5</maxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
<!-- valid logging levels: TRACE, DEBUG, INFO, WARN, ERROR -->
<logger name="org.apache.nifi" level="INFO"/>
<logger name="org.apache.nifi.processors" level="WARN"/>
<logger name="org.apache.nifi.processors.standard.LogAttribute" level="INFO"/>
<logger name="org.apache.nifi.processors.standard.LogMessage" level="INFO"/>
<logger name="org.apache.nifi.controller.repository.StandardProcessSession" level="WARN" />
<logger name="org.apache.zookeeper.ClientCnxn" level="ERROR" />
<logger name="org.apache.zookeeper.server.NIOServerCnxn" level="ERROR" />
<logger name="org.apache.zookeeper.server.NIOServerCnxnFactory" level="ERROR" />
<logger name="org.apache.zookeeper.server.quorum" level="ERROR" />
<logger name="org.apache.zookeeper.ZooKeeper" level="ERROR" />
<logger name="org.apache.zookeeper.server.PrepRequestProcessor" level="ERROR" />
<logger name="org.apache.calcite.runtime.CalciteException" level="OFF" />
<logger name="org.apache.curator.framework.recipes.leader.LeaderSelector" level="OFF" />
<logger name="org.apache.curator.ConnectionState" level="OFF" />
<!-- Logger for managing logging statements for nifi clusters. -->
<logger name="org.apache.nifi.cluster" level="INFO"/>
<!-- Logger for logging HTTP requests received by the web server. -->
<logger name="org.apache.nifi.server.JettyServer" level="INFO"/>
<!-- Logger for managing logging statements for jetty -->
<logger name="org.eclipse.jetty" level="INFO"/>
<!-- Suppress non-error messages due to excessive logging by class or library -->
<logger name="org.springframework" level="ERROR"/>
<!-- Suppress non-error messages due to known warning about redundant path annotation (NIFI-574) -->
<logger name="org.glassfish.jersey.internal.Errors" level="ERROR"/>
<!-- Suppress non-error messages due to Jetty AnnotationParser emitting a large amount of WARNS. Issue described in NIFI-5479. -->
<logger name="org.eclipse.jetty.annotations.AnnotationParser" level="ERROR"/>
<!-- Suppress non-error messages from SSHJ which was emitting large amounts of INFO logs by default -->
<logger name="net.schmizz.sshj" level="WARN" />
<logger name="com.hierynomus.sshj" level="WARN" />
<!-- Suppress non-error messages from SMBJ which was emitting large amounts of INFO logs by default -->
<logger name="com.hierynomus.smbj" level="WARN" />
<!-- These log messages would normally go to the USER_FILE log, but they belong in the APP_FILE -->
<logger name="org.apache.nifi.web.security.requests" level="INFO" additivity="false">
<appender-ref ref="APP_FILE"/>
</logger>
<!--
Logger for capturing user events. We do not want to propagate these
log events to the root logger. These messages are only sent to the
user-log appender.
-->
<logger name="org.apache.nifi.web.security" level="INFO" additivity="false">
<appender-ref ref="USER_FILE"/>
</logger>
<logger name="org.apache.nifi.web.api.config" level="INFO" additivity="false">
<appender-ref ref="USER_FILE"/>
</logger>
<logger name="org.apache.nifi.authorization" level="INFO" additivity="false">
<appender-ref ref="USER_FILE"/>
</logger>
<logger name="org.apache.nifi.cluster.authorization" level="INFO" additivity="false">
<appender-ref ref="USER_FILE"/>
</logger>
<logger name="org.apache.nifi.web.filter.RequestLogger" level="INFO" additivity="false">
<appender-ref ref="USER_FILE"/>
</logger>
<logger name="org.apache.nifi.web.api.AccessResource" level="INFO" additivity="false">
<appender-ref ref="USER_FILE"/>
</logger>
<!--
Logger for capturing Bootstrap logs and NiFi's standard error and standard out.
-->
<logger name="org.apache.nifi.bootstrap" level="INFO" additivity="false">
<appender-ref ref="BOOTSTRAP_FILE" />
</logger>
<logger name="org.apache.nifi.bootstrap.Command" level="INFO" additivity="false">
<appender-ref ref="CONSOLE" />
<appender-ref ref="BOOTSTRAP_FILE" />
</logger>
<!-- Everything written to NiFi's Standard Out will be logged with the logger org.apache.nifi.StdOut at INFO level -->
<logger name="org.apache.nifi.StdOut" level="INFO" additivity="false">
<appender-ref ref="BOOTSTRAP_FILE" />
</logger>
<!-- Everything written to NiFi's Standard Error will be logged with the logger org.apache.nifi.StdErr at ERROR level -->
<logger name="org.apache.nifi.StdErr" level="ERROR" additivity="false">
<appender-ref ref="BOOTSTRAP_FILE" />
</logger>
<root level="INFO">
<appender-ref ref="APP_FILE" />
</root>
</configuration>
# 나이파이 재시작
${NIFI_HOME}/bin/nifi.sh stop
${NIFI_HOME}/bin/nifi.sh start
# 경로 이동
cd /opt/apps
# 압축 파일 다운로드
wget https://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
# 압축 해제
tar xvfz sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
# 폴더명변경
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1.4.7
chown -R hadoop:hadoop ./sqoop-1.4.7
# 추가로 필요한 파일입니다. 압축 해제 후 필요 파일을 복사합니다.
wget https://archive.apache.org/dist/commons/lang/binaries/commons-lang3-3.12.0-bin.tar.gz
tar xvfz commons-lang3-3.12.0-bin.tar.gz
cp /opt/apps/commons-lang3-3.12.0/commons-lang3-3.12.0.jar /opt/apps/sqoop-1.4.7/lib
mv /opt/apps/sqoop-1.4.7/lib/commons-lang3-3.4.jar /opt/apps/sqoop-1.4.7/lib/commons-lang3-3.4.jar.backup
# 권한 부여
chown -R hadoop:hadoop /opt/apps/sqoop-1.4.7
2. Sqoop 환경 변수 등록
action server: mast01
user: root
pwd: /opt/apps
cmd:
# 환경변수등록
vi /etc/profile.d/sqoop.sh
export SQOOP_HOME=/opt/apps/sqoop-1.4.7
export SQOOP_CONF_DIR=$SQOOP_HOME/conf
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$SQOOP_HOME/bin
# 환경변수적용
source /etc/profile.d/sqoop.sh
# 계정 전환
su - hadoop
# 경로 이동
cd /opt/apps/sqoop-1.4.7/
3. Sqoop 파일 복사 및 수정
action server: mast01
user: hadoop
pwd: /opt/apps/sqoop-1.4.7
cmd:
# 파일 복사 및 수정
cp conf/sqoop-env-template.sh conf/sqoop-env.sh
vi conf/sqoop-env.sh
export HADOOP_COMMON_HOME=/opt/apps/hadoop-3.2.1
export HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.2.1
export HBASE_HOME=/opt/apps/hbase-2.3.7
export HIVE_HOME=/opt/apps/hive-3.1.2
export ZOOCFGDIR=/opt/apps/zookeeper-3.5.10
export HCAT_HOME=$HIVE_HOME/hcatalog
# postgresql-42.6.0.jar를 구해야합니다.
cp /opt/apps/postgresql-42.6.0.jar /opt/apps/sqoop-1.4.7/lib/
cp /opt/apps/sqoop-1.4.7/sqoop-1.4.7.jar /opt/apps/hadoop-3.2.1/share/hadoop/tools/lib/