cd /opt/apps
wget https://archive.apache.org/dist/spark/spark-3.2.3/spark-3.2.3-bin-hadoop3.2.tgz
tar xvfz spark-3.2.3-bin-hadoop3.2.tgz
mv spark-3.2.3-bin-hadoop3.2/ spark-3.2.3
cd /opt/apps/spark-3.2.3/
2. Spark 설정파일 수정
action server: mast01
user: root
pwd: /opt/apps/spark-3.2.3
cmd:
vi conf/spark-env.sh
export JAVA_HOME=/opt/apps/jdk8
export HADOOP_HOME=/opt/apps/hadoop-3.3.5
export SPARK_HOME=/opt/apps/spark-3.3.5
export HADOOP_CONF_DIR=/opt/apps/hadoop-3.3.5/etc/hadoop
export YARN_CONF_DIR=/opt/apps/hadoop-3.3.5/etc/hadoop
# ssh 포트가 디폴트가 아니면 해당 행 추가
export SPARK_SSH_OPTS="-p 22002"
export SPARK_MASTER_WEBUI_PORT=28877
export SPARK_WORKER_WEBUI_PORT=28888
export SPARK_MASTER_URL=spark://mast01:7077
export SPARK_LOCAL_DIRS=/opt/apps/spark-3.2.3
export SPARK_WORKER_MEMORY=2g
export SPARK_EXECUTOR_MEMORY=2g
export SPARK_MASTER_IP=mast01
vi conf/spark-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://NNHA:8020/user/spark/log
spark.history.fs.logDirectory hdfs://NNHA:8020/user/spark/log
# 로그 삭제 주기 설정
spark.history.fs.cleaner.enabled true
spark.history.fs.cleaner.maxAge 7d
spark.history.fs.cleaner.interval 1d
# 실행권한 부여
chmod 755 conf/spark-env.sh
# workers 작성
vi conf/workers
work01
work02
work03
# work01~03 서버 실행
cd /opt/apps
tar xvfz spark.tar.gz
# mast01, work01~03 서버 실행
chown -R hadoop:hadoop /opt/apps/spark-3.2.3
vi /etc/profile.d/spark.sh
export SPARK_HOME=/opt/apps/spark-3.2.3
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$SPARK_HOME/sbin
source /etc/profile.d/spark.sh
su - hadoop
cd /opt/apps/spark-3.2.3
cd /opt/apps
wget https://archive.apache.org/dist/nifi/1.12.0/nifi-1.12.0-bin.tar.gz
tar xvfz nifi-1.12.0-bin.tar.gz
chown -R hadoop:hadoop /opt/apps/nifi-1.12.0
2. nifi 데이터 저장소 결로 생성 및 권한 부여
action server: mast03
user: root
pwd: -
cmd:
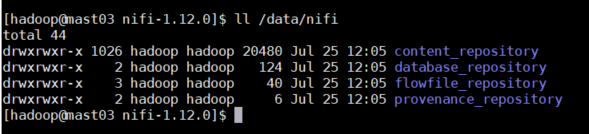
mkdir /data/nifi
chown -R hadoop:hadoop /data/nifi
su - hadoop
cd /opt/apps/nifi-1.12.0
3. nifi 설정파일 수정
action server: mast03
user: hadoop
pwd: /opt/apps/nifi-1.12.0
cmd:
vi conf/nifi.properties
# 엡 포트 지정
nifi.web.http.port=18080
# nifi 데이터 저장 경로 지정
nifi.database.directory=/data/nifi/database_repository
nifi.flowfile.repository.directory=/data/nifi/flowfile_repository
nifi.content.repository.directory.default=/data/nifi/content_repository
nifi.provenance.repository.directory.default=/data/nifi/provenance_repository
# git 설치
yum install -y git
# 빌드과정에서 필요한 패키지설치
yum install -y bzip2
yum install protobuf
yum install protobuf-compiler
# 경로 이동
cd /opt/apps
# git clone
git clone https://github.com/apache/tez.git
# 경로 이동
cd tez
# git branch변경
git checkout branch-0.10.2
# 태그변경확인
git branch
# 경로 이동
cd ..
2. tez 폴더 권한 변경
action server: mast02
user: root
pwd: /opt/apps/
cmd:
# 빌드 시 root계정으로 빌드 될 수 없다는 에러가 나옵니다.
chown -R hadoop:hadoop ./tez
su - hadoop
cd /opt/apps/tez
3. pom.xml 수정
action server: mast02
user: hadoop
pwd: /opt/apps/tez
cmd:
vi pom.xml
# 디폴트값
<guava.version>31.1-jre</guava.version>
<hadoop.version>3.3.1</hadoop.version>
# 설치된 하둡버전과 구아바 버전에 맞게 변경
<guava.version>27.0-jre</guava.version>
<hadoop.version>3.3.5</hadoop.version>
# 아래는 아래 에러가 난다면 수정해주세요.
# bower alasql#^0.4.0 CERT_HAS_EXPIRED Request to https://registry.bower.io/packages/alasql failed: certificate has expired
vi tez-ui/pom.xml
<allow-root-build>--allow-root=false</allow-root-build> 이 부분을
<allow-root-build>--config.strict-ssl=false --allow-root=false</allow-root-build> 이렇게 수정해주세요.
su - postgres
# 다른 포트로 설치하였습니다.
psql -p 14325
create user hive password 'hive';
create database hive owner hive;
grant all privileges on database hive to hive;
\connect hive;
\q
# root계정 전환
exit
2. Hive 압축파일 다운로드
action server: mast02
user: root
pwd: -
cmd:
cd /opt/apps
wget https://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
# 압축 해제 및 이름 변경
tar xvfz apache-hive-3.1.3-bin.tar.gz
mv apache-hive-3.1.3-bin hive-3.1.3
3. Hive 환경변수 지정 및 권한 변경
action server: mast02
user: root
pwd: -
cmd:
chown -R hadoop:hadoop /opt/apps/hive-3.1.3
vi /etc/profile.d/hive.sh
export HIVE_HOME=/opt/apps/hive-3.1.3
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile.d/hive.sh
# 계정 전환 및 경로 이동
su - hadoop
cd /opt/apps/hive-3.1.3
4. Hive 설정 파일 수정
action server: mast02
user: hadoop
pwd: /opt/apps/hive-3.1.3
cmd:
cp conf/hive-env.sh.template conf/hive-env.sh
# hive 실행 환경 수정
vi conf/hive-env.sh
HADOOP_HOME=/opt/apps/hadoop-3.3.5
export HIVE_AUX_JARS_PATH=/opt/apps/hive-3.1.3/lib/
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
if [ "${HIVE_AUX_JARS_PATH}" != "" ]; then
if [ -f "${HIVE_AUX_JARS_PATH}" ]; then
export HIVE_AUX_JARS_PATH=${HIVE_AUX_JARS_PATH}
elif [ -d "/opt/apps/hive-3.1.3/hcatalog/share/hcatalog" ]; then
export HIVE_AUX_JARS_PATH=/opt/apps/hive-3.1.3/hcatalog/share/hcatalog/hive-hcatalog-core-3.1.3.jar
fi
elif [ -d "/opt/apps/hive-3.1.3/hcatalog/share/hcatalog" ]; then
export HIVE_AUX_JARS_PATH=/opt/apps/hive-3.1.3/hcatalog/share/hcatalog/hive-hcatalog-core-3.1.3.jar
fi
# hive 설정 변경
vi conf/hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:postgresql://mast02:14325/hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.postgresql.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
</property>
<property>
<name>hive.security.authorization.sqlstd.confwhitelist.append</name>
<value>mapreduce.*|mapred.*|hadoop.*|user*|password*|hive.*</value>
</property>
<property>
<name>hive.strict.managed.tables</name>
<value>false</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.user.install.directory</name>
<value>/user/</value>
</property>
<property>
<name>hive.exec.parallel</name>
<value>true</value>
</property>
<property>
<name>hive.exec.parallel.thread.number</name>
<value>8</value>
</property>
</configuration>
cp conf/hive-log4j2.properties.template conf/hive-log4j2.properties
chmod 755 conf/hive-log4j2.properties
# hive log 디렉토리지정
vi conf/hive-log4j2.properties
property.hive.log.dir = /data/hive/log
property.hive.log.file = hive.log
# hive log 디렉토리 생성 및 권한 부여
exit
mkdir -p /data/hive/log
chown -R hadoop:hadoop /data/hive/
su - hadoop
cd /opt/apps/hive-3.1.3
5. jar 파일 변경 및 추가
action server: mast02
user: hadoop
pwd: /opt/apps/hive-3.1.3
cmd:
# hadoop의 구아바버전과 동일하게 설정
find ./ -name guava*.jar -> 구아바 파일 찾기
rm -rf ./lib/guava-19.0.jar -> 해당 하이브는 구아바 19버전을 사용하였습니다.
# 하둡 폴더 내의 구아바파일을 복사합니다.
cp ../hadoop-3.3.5/share/hadoop/common/lib/guava-27.0-jre.jar ./lib
# postgresql.jar파일을 업로드합니다.
cp postgresql-42.2.6.jar /opt/apps/hive-3.1.3/lib/
# 업로드 후 파일 권한들 hadoop:hadoop으로 되어있는지 확인해주세요!
vi [pg_data위치]/pg_hba.conf
# 맨 밑 부분
# TYPE DATABASE USER ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 trust
# 해당 행은 10.10.50으로 시작하는 ip는 허용한다는 뜻
host all all 10.10.50.0/24 md5
# IPv6 local connections:
host all all ::1/128 trust
# Allow replication connections from localhost, by a user with the
# replication privilege.
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all ::1/128 trust
psql: could not connect to server: No such file or directory Is the server running locally and accepting connections on Unix domain socket "/var/run/postgresql/.s.PGSQL.5432"?
cd /usr
chown -R postgres:postgres pgsql-11
mkdir /data/postgres
chown -R postgres:postgres /data/postgres
su - postgres
/usr/pgsql-11/bin/initdb -D /data/postgres/pg_data
3. PostgreSQL 컨피그파일 수정
vi /data/postgres/pg_data/postgresql.conf
# 주석 해제 후 입력
listen_addresses = '*'
port = [원하는포트]
vi /data/postgres/pg_data/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 trust
# 해당 행 추가 / 10.10.50 대역의 ip를 받겠다는 뜻
host all all 10.10.50.0/24 md5
# IPv6 local connections:
host all all ::1/128 trust
# Allow replication connections from localhost, by a user with the
# replication privilege.
local replication all trust
host replication all 127.0.0.1/32 trust