* 본 가이드는 필요 파일과 이전 포스팅까지 작업이 완료되었다는 가정하에 진행
주요 스펙
호스트OS - windows10 home
게스트OS들 - centOS7
Hadoop - 3.1.0
Zookeeper - 3.4.10
jdk - 1.8.0_191
MobaXterm을 활용하여 작업 진행
공유기(WI-FI) 연결 환경
서버 6대를 활용한 하둡 HA 구성:
nn01: 액티브 네임노드, 저널노드 역할
rm01: 스탠바이 네임노드, 리소스 매니저, 저널노드 역할
jn01: 저널노드 역할
dn01: 데이터 노드 역할
dn02: 데이터 노드 역할
dn03: 데이터 노드 역할
실행 환경:
Action Server: 명령을 수행할 서버(hostname)
User: 명령을 수행할 계정
Pwd: 명령을 수행할 경로
지난 시간엔 하둡(hadoop)과 주키퍼(zookeeper)를 사용할 계정을 생성하고 권한 부여 및 ssh 통신 설정을 마쳤습니다.
이번 포스팅에서는 주키퍼 계정에 직접 주키퍼를 설하는 과정을 진행하겠습니다.
ssh 통신이 설정되어있지 않으면 본 과정을 진행 시 차질이 있습니다. 설정은 마친 후 진행해주세요!
developer-woong.tistory.com/19
(하둡 설치) ep06_하둡(hadoop), 주키퍼(zookeeper) 계정 생성 및 권한 설정, ssh 통신
* 본 가이드는 필요 파일과 이전 포스팅까지 작업이 완료되었다는 가정하에 진행 주요 스펙 호스트OS - windows10 home 게스트OS들 - centOS7 Hadoop - 3.1.0 Zookeeper - 3.4.10 jdk - 1.8.0_191 MobaXterm을 활..
developer-woong.tistory.com
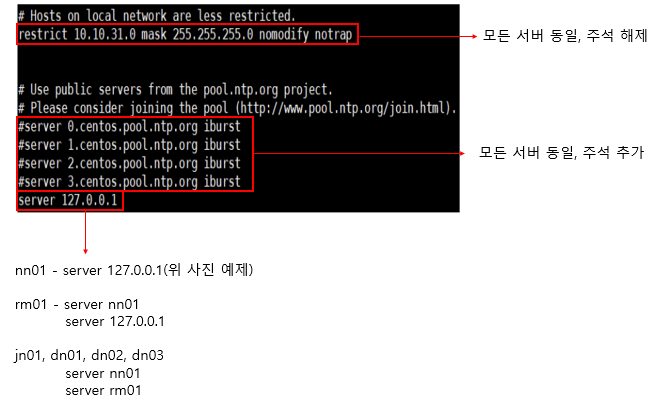
* 주키퍼(zookeeper)는 nn01, rm01, jn01에서만 설치되며, nn01서버의 zookeeper계정에 먼저 설치 후, 파일 설정을 마치고 rm01, jn01에게 배포하는 방식으로 진행
주키퍼(zookeeper) 계정 접속 - nn01서버만
Action Server: nn01
User: root
Pwd: /root
# nn01에서 설치 및 환경 설정 후 rm01, jn01서버에 배포
# 사용자 변경
su - zookeeper
주키퍼(zookeeper) 설치
Action Server: nn01
User: zookeeper
Pwd: /home/zookeeper
# wget이 없다면 설치
# yum install wget
# 주키퍼 다운로드 (본 가이드에서는 3.4.10v)
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.10.tar.gz
주키퍼(zookeeper) 압축 파일 해제
Action Server: nn01
User: zookeeper
Pwd: /home/zookeeper
# 압축 해제
tar xvfz zookeeper-3.4.10.tar.gz
# 확인
ls
주키퍼(zookeeper) config 파일 접근
Action Server: nn01
User: zookeeper
Pwd: /home/zookeeper
# 경로 이동
cd zookeeper-3.4.10
주키퍼(zookeeper) config 파일 수정
Action Server: nn01
User: zookeeper
Pwd: /home/zookeeper/zookeeper-3.4.10
# 파일 복사
cp conf/zoo_sample.cfg conf/zoo.cfg
# 파일 수정
vi conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/zookeeper/data
clientPort=2181
maxClientCnxns=0
maxSessionTimeout=180000
server.1=nn01:2888:3888
server.2=rm01:2888:3888
server.3=jn01:2888:3888

주키퍼(zookeeper) 재압축을 위한 경로 이동
Action Server: nn01
User: zookeeper
Pwd: /home/zookeeper/zookeeper-3.4.10
# 경로 이동
cd ..
# pwd -> home/zookeeper
주키퍼(zookeeper) 재압축
Action Server: nn01
User: zookeeper
Pwd: /home/zookeeper
# 폴더 이름 확인
ls
# 위 과정을 통해 zoo.cfg 파일 설정을 마쳤으니 재압축 후 rm01, jn01 서버에 배포할 것
# zookeeper.tar.gz 이름으로 재 압축
tar cvfz zookeeper.tar.gz zookeeper-3.4.10
# 확인
ls
주키퍼(zookeeper) 재압축 파일 배포
Action Server: nn01
User: zookeeper
Pwd: /home/zookeeper
# rm01, jn01서버에 배포
# 오류 시 ssh 설정 다시 확인
scp zookeeper.tar.gz zookeeper@server02:/home/zookeeper
scp zookeeper.tar.gz zookeeper@server03:/home/zookeeper
배포한 재압축 주키퍼(zookeeper)파일 압축 해제
Action Server: rm01, jn01
User: zookeeper
Pwd: /home/zookeeper
# 배포받은 rm01, jn01서버에서 압축 해제
# zookeeper 계정으로 접속후 진행
tar xvfz zookeeper.tar.gz
# 확인
ls
주키퍼(zookeeper) myid 지정
Action Server: nn01, rm01, jn01
User: zookeeper
Pwd: /home/zookeeper
# data 폴더 생성
mkdir data
# 경로 이동
cd data
# id 생성
# nn01은 1, rm01은 2, jn01은 3 적어주고 wq!
vi myid
# 돌아오기
cd ~


주키퍼(zookeeper) 서버 실행
Action Server: nn01, rm01, jn01
User: zookeeper
Pwd: /home/zookeeper
# 경로 이동
cd zookeeper-3.4.10
# 주키퍼 서버 실행
./bin/zkServer.sh start
주키퍼(zookeeper) 서버 상태 확인
Action Server: nn01, rm01, jn01
User: zookeeper
Pwd: /home/zookeeper
# 서버 별 상태 확인
./bin/zkServer.sh status
# 한 서버는 leader, 두 서버는 follower, 모든 서버가 실행중이어야 정상적으로 출력됩니다
# 실행 시 마다 달라질 수 있음. 비율은 맞아야 함


주키퍼(zookeeper) 서버 종료
Action Server: nn01, rm01, jn01
User: zookeeper
Pwd: /home/zookeeper
./bin/zkServer.sh stop
이렇게 주키퍼(zookeeper) 설치 및 환경 설정까지 마치고 서버까지 실행시켜보았습니다.
다음 시간에는 하둡(hadoop) 설치에 대해 포스팅하겠습니다.
감사합니다!!!
developer-woong.tistory.com/21
(하둡 설치) ep08_하둡(hadoop)설치 및 환경 설정
* 본 가이드는 필요 파일과 이전 포스팅까지 작업이 완료되었다는 가정하에 진행 주요 스펙 호스트OS - windows10 home 게스트OS들 - centOS7 Hadoop - 3.1.0 Zookeeper - 3.4.10 jdk - 1.8.0_191 MobaXterm을 활..
developer-woong.tistory.com
'BigData > Hadoop' 카테고리의 다른 글
| (하둡 설치) ep09_하둡(hadoop) 실행과 종료, 트러블 슈팅 (2) | 2021.02.25 |
|---|---|
| (하둡 설치) ep08_하둡(hadoop)설치 및 환경 설정 (0) | 2021.02.25 |
| (하둡 설치) ep06_하둡(hadoop), 주키퍼(zookeeper) 계정 생성 및 권한 설정, ssh 통신 (0) | 2021.02.25 |
| (하둡 설치) ep05_MobarXterm 원격 ssh접속 및 STFP 활용 centOS7 java(jdk) 환경 설정 (0) | 2021.02.25 |
| (하둡 설치) ep04_게스트OS간 통신(SELINUX, SSH, NTP, 방화벽) (0) | 2021.02.20 |