192.168.10.1(mast01), 192.168.10.2(mast02), 192.168.10.3(mast03), 192.168.10.4(work01), 192.168.10.5(work02), 192.168.10.6(work03), 192.168.10.4(work04)의 서버들이 각각 자신의 호스트명을 등록하고 다른 서버들과
# hdfs 상의 루트 디렉토리 조회
hdfs dfs -ls /
# /user 디렉토리 생성
hdfs dfs -mkdir /user
# /user 디렉토리 하위에 /hadoop 디렉토리 생성
hdfs dfs -mkdir /user/hadoop
# /user/hadoop 디렉토리 하위에 /conf 디렉토리 생성
hdfs dfs -mkdir /user/hadoop/conf
# 워드카운트 예제에 사용할 hadoop-env.sh 파일을 HDFS의 /user/hadoop/conf 디렉토리로 이동
hdfs dfs -put /home/hadoop/hadoop-3.1.0/etc/hadoop/hadoop-env.sh /user/hadoop/conf/
# 파일 이동 확인
hdfs dfs -ls /user/hadoop/conf
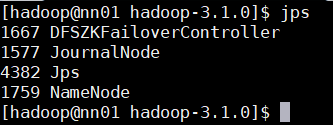
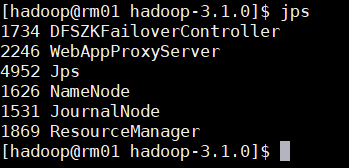
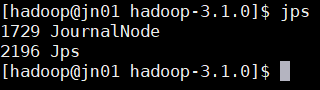
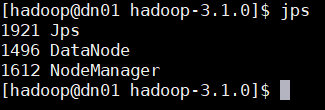
맵리듀스(MapReduce) 확인
Action Server: nn01
User: hadoop
Pwd: /home/hadoop
# wordcount 실행
# yarn jar [jar파일 경로] wordcount [워드카운트를 실행할 파일이 위치한 폴더명] [워드카운트 결과를 저장할 폴더명]
yarn jar /home/hadoop/hadoop-3.1.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar
wordcount conf output
# wordcount 결과 파일 생성 조회
hdfs dfs -ls /user/hadoop/output/
워드카운트(WordCount) 확인
Action Server: nn01
User: hadoop
Pwd: /home/hadoop
# wordcount 결과 확인 (파일의 단어 갯수)
hdfs dfs -cat /user/hadoop/output/part-r-00000
하둡 클러스터(hadoop cluster)종료
주의!
1. 차례대로 실행한다.
2. 종료는 실행의 역순으로 진행
3. 마찬가지로 명령어마다 실행 서버가 다르므로 설명 참고!
# rm01, 얀 클러스터 종료
./sbin/stop-yarn.sh
# rm01, 스탠바이 네임노드용 주키퍼 장애 컨트롤러 종료
./bin/hdfs --daemon stop zkfc
# rm01, 스탠바이 네임노드 종료
./bin/hdfs --daemon stop namenode
# nn01, 전체 데이터 노드 종료 daemons s 꼭 붙이기
./sbin/hadoop-daemons.sh stop datanode
# nn01, 액티브 네임노드용 주키퍼 장애 컨트롤러 종료
./bin/hdfs --daemon stop zkfc
# nn01, 액티브 네임노드 종료
./bin/hdfs --daemon stop namenode
# nn01, rm01, jn01 각 저널노드 종료)
./bin/hdfs --daemon stop journalnode
주키퍼(zookeeper) 서버 종료
Action Server: nn01, rm01, jn01
User: zookeeper
Pwd: /home/zookeeper
./bin/zkServer.sh stop
이 것으로 서버 6대를 활용한 하둡 고가용성(HA) 모드 클러스터를 구축하고 워드카운트 예제까지 실행하며 정상 동작하는 것을 확인하였습니다!!
앞으로는 NIFI, HIVE등의 하둡에 밀접한 관계를 가진 프레임워크 혹은 프로그램들과 연동하며 효율적인 빅데이터 활용을 위해 공부해나가는 포스팅을 하도록 하겠습니다.
긴 글 읽어주셔서 너무나도 감사드리고 하둡 설치 가이드 중 잘못 설명되어있다면 피드백은 언제나 감사드리고
vi hadoop-env.sh
# vi 편집기 표준 모드 상태에서 (esc누르면 표준 모드)
# 원하는 줄의 숫자를 타이핑 후(보이진 않음) Shift + G 시 해당 줄로 이동
# 54번째 줄
export JAVA_HOME=/opt/apps/jdk8/ # 주석 해제 후 입력
# 211번째 줄
export HADOOP_PID_DIR=/pids # 주석 해제 후 입력
하둡(hadoop)파일 재압축을 위해 경로 이동
Action Server: nn01
User: hadoop
Pwd: /home/hadoop/hadoop-3.1.0/etc/hadoop
# 경로 변경
cd ~ (pwd -> /home/hadoop)
하둡(hadoop)파일 재압축
Action Server: nn01
User: hadoop
Pwd: /home/hadoop
# hadoop.tar.gz이라는 이름으로 재압축
tar cvfz hadoop.tar.gz hadoop-3.1.0
# 확인
ls
하둡(hadoop)파일 배포
Action Server: nn01
User: hadoop
Pwd: /home/hadoop
# 다른 5대의 서버에 배포
# 에러 시 ssh 연결 확인
scp hadoop.tar.gz hadoop@rm01:/home/hadoop
scp hadoop.tar.gz hadoop@jn01:/home/hadoop
scp hadoop.tar.gz hadoop@dn01:/home/hadoop
scp hadoop.tar.gz hadoop@dn02:/home/hadoop
scp hadoop.tar.gz hadoop@dn03:/home/hadoop
하둡(hadoop)재압축 파일 압축 해제
Action Server: rm01, jn01, dn01, dn02, dn03
User: hadoop
Pwd: /home/hadoop
# hadoop계정으로 전환 후 작업
su - hadoop
# 배포받은 재압축 파일 압축 해제
tar xvfz hadoop.tar.gz
root계정으로 전환 (모든 서버)
Action Server: all
User: hadoop
Pwd: /home/hadoop
# 모든 서버에서 실행, 하둡 환경변수 작업을 위한 계정 전환
exit
하둡(hadoop) 환경변수 설정 (모든 서버)
Action Server: all
User: root
Pwd: /root
# 하둡 환경변수 설정
vi /etc/profile.d/hadoop.sh
export HADOOP_HOME=/home/hadoop/hadoop-3.1.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# 작성 내역 적용
source /etc/profile.d/hadoop.sh